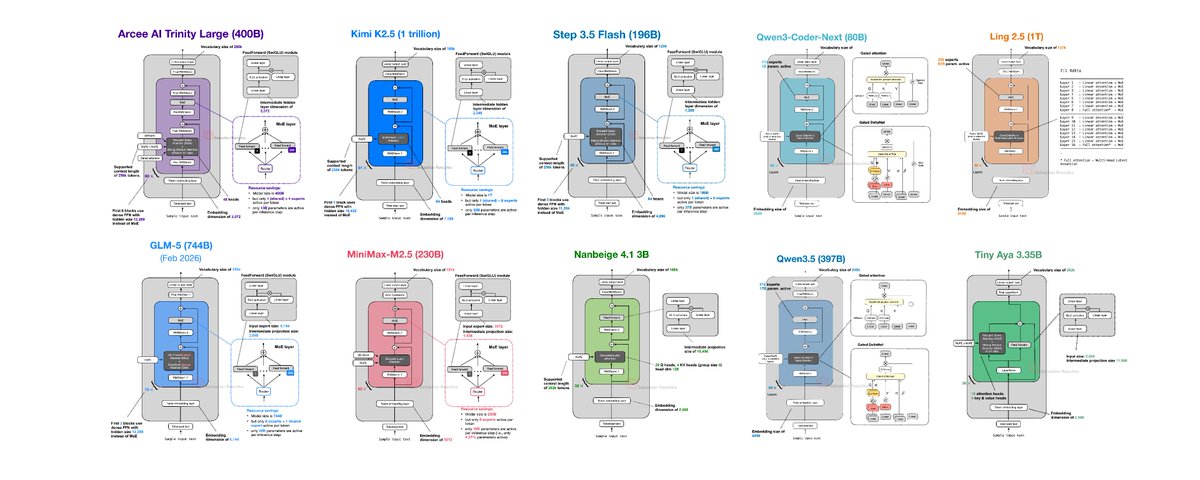
If you have struggled to keep up with open-weight releases this past month, here's an overview of the main ones in chronological order with a focus on the architecture designs.
1) Arcee AI Trinity Large (Jan 27)
Arcee's Trinity line came out of nowhere for many of us. It's a 400B MoE (13B active), plus two smaller smaller variants. Architecturally, it combines familiar ingredients: Mixture-of-Experts (MoE) + Grouped Query Attention (GQA) + Sliding Window Attention (SWA).
2) Moonshot Kimi K2.5 (Jan 27)
Similar to Kimi K2, Kimi K2.5 is one of the largest open-weight models at 1 trillion parameters. Also similar to Kimi K2, it follows a DeepSeek-like template.
3) StepFun Step 3.5 Flash (Feb 1)
Step 3.5 Flash mainly focuses on performance-throughput balance. Overall, it is somewhat to Arcee Trinity in that it uses GQA + SWA, but it's 2x smaller.
4) Qwen3-Coder-Next (Feb 3)
Qwen3-Coder-Next continues Qwen's focus on hybrid-attention for coding models. The architecture (and size) is similar to the previous 80B Qwen3-Next model, except it's fine-tuned for coding contexts.
5) z.AI GLM-5 (Feb 12)
GLM-5 is a flagship-scale release that stays close to the current “large MoE + efficiency tweaks” consensus. It also includes DeepSceek-inspired choices (for example, MLA and DeepSeek Sparse Attention).
6) MiniMax M2.5 (Feb 12)
Related threads