

Page 1 • Showing 12 tweets
found this must-read article by @steipete from just a few weeks ago. he breaks down his AI coding approach after months of shipping non stop with agents. > Codex may be 4x slower per task than Claude Code but it’s faster overall since you don’t have to fix the fix. > he barely reads code anymore, instead he understands the system architecture and component layout. the important decisions are about choosing languages, ecosystems, and dependencies, not writing code. > start everything as CLI. anything he builds begins as CLI. it’s easier to debug and code for the agents. > commits straight to main. almost never uses branches/worktrees, also no issue trackers. > maintains a docs/ folder per project and a global AGENTS. MD that gives the model enough context. he designs codebases to be understood by agents, not humans. https://steipete.me/posts/2025/shipping-…

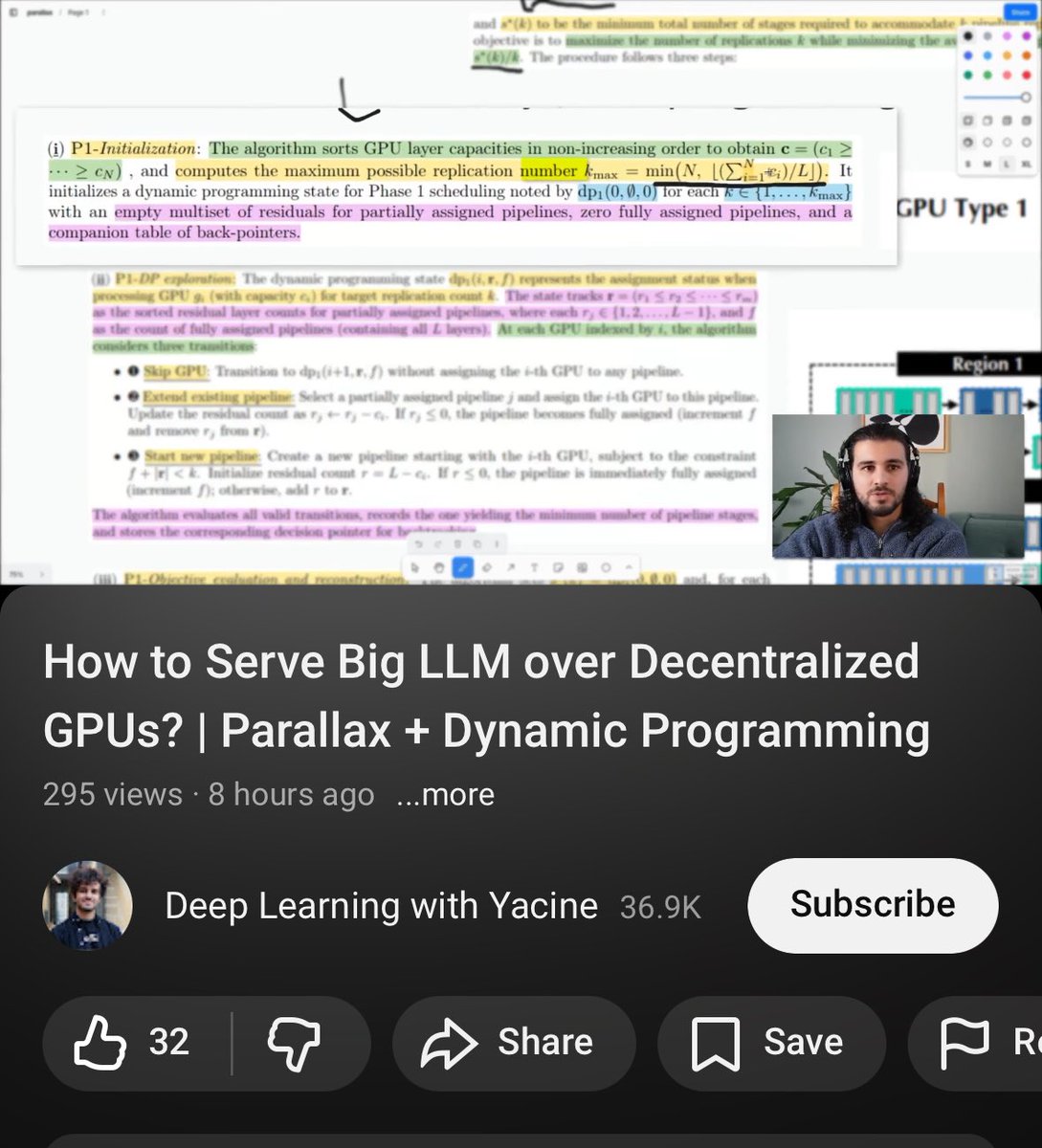
this is a great video to watch if you’re interested in the programming and computational challenges of serving a big LLM over decentralized GPUs. yet again @yacinelearning delivers 🔥
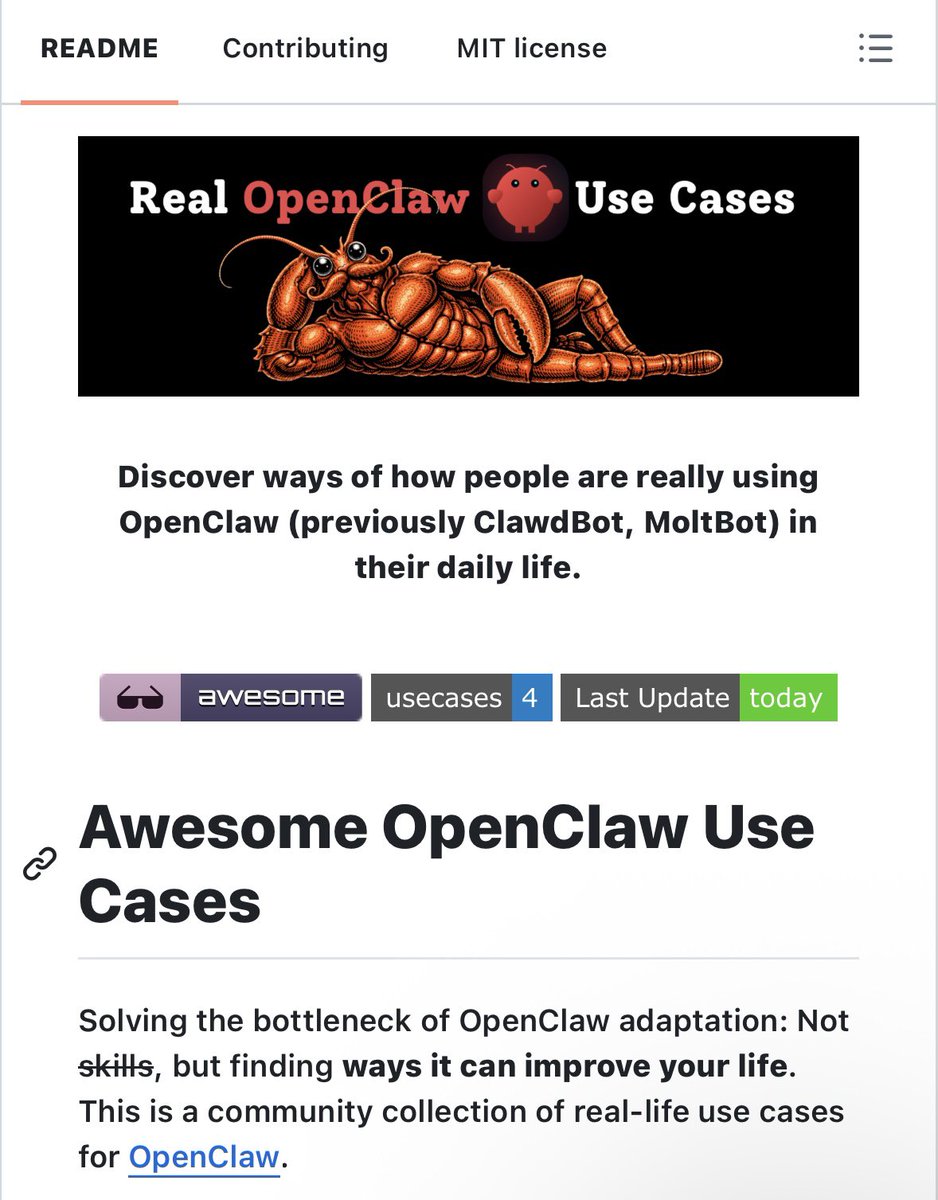
okay so what’s the real use case of OpenClaw? this is the question i see the most. there are >3000 skills available but very few ideas on what to use them for. the ideas get lost in reddit and X. i made a repo for this bottleneck. open a PR and let others know about real use cases. i already started with 4 workflows i already run with my OpenClaw, but i’m calling for contributions. i know people are doing crazy stuff with OpenClaw out there. check it out here: https://github.com/hesamsheikh/awesome-o…
bro runs OpenClaw on a $25 Android phone, giving AI access to hardware. proof no. 17374 that you don’t need Mac Minis to run OpenClaw. just get an old phone or raspberry pie.

Developers today: 50% in denial, 25% in anger, 20% bargaining, 5% depression and acceptance.

“okay ClawdBot, every morning fix my life, make no mistakes or you will be unplugged”

this advice from Dan Koe is super relevant right now. if you have multiple interests, take the next 2-3 years seriously.

I took a look inside Clawdbot (aka Moltbot) architecture and how it handles agent executions, tool use, browser, etc. there are many lessons to learn for AI engineers. learning how Clawd works under the hood allows a better understanding of the system and its capabilities, and most importantly, what it's GOOD at and BAD at. this started as a personal curiosity about how Clawd handles its memory and how reliable it is. in this article i'll go through the surface-level of how Clawd works. # What Clawd is TECHNICALLY so everybody knows Clawd is a personal assistant you can run locally or through model APIs and access as easy as on your phone. but what is it really? at its core, Clawdbot is a Typescript CLI application. it's not Python, Next.js, or a web app. it's a process that > runs on your machine and exposes a gateway server to handle all channel connections (telegram, whatsapp, slack, etc.) > makes calls to LLM APIs (Anthropic, OpenAI, local, etc.) > executes tools locally, > and does whatever you want on your computer. # The Architecture to explain the architecture more simply, here's an example of what happens when you message Clawd all the way to how you get an output. here's what happens when you prompt Clawd on a messanger: ## 1. Channel Adapter A Channel Adapter takes you message and processes it (normalize, extract attachments). Different messengers and input streams have their dedicated adapters. ## 2. Gateway Server The Gateway Server which is the task/session coordinator takes your message and passes it to the right session. this is the heart of the Clawd. It handles multiple overlapping requests. to serialize operations, Clawd uses a lane-based command queue. A session has its own dedicated lane, and low-risk parallizable tasks can run in parallel lanes (crone jobs). This is in contrast to using async/await spaghetti. over parallilization hurts reliability and brings out a huge swarm of debugging nightmares. > Default to Serial, go for Parallel explicitly if you've worked with agents you've already realized this to some extent. this is also the insight from Cognition's Don’t Build Multi-Agents blog post. a simple async setup per agent will leave you with a dump of interleaved garbage. logs will be unreadable, and if they share states, race conditions will be a constant fear you must account for in development. Lane is an abstraction over queues with serialization is the default architecture instead of an afterthought. as a developer, you write code manually, and the queue handles the race conditions for you. the mental model shifts from "what do I need to lock?" to "what's safe to parallalize?" ## 3. Agent Runner this is where the actual AI comes in. it figures out which model to use, picks the API key (if none work it marks the profile in cooldown and tries next), and falls back to a different model if the primary one fails. the agent runner assembles the system prompt prompt dynamically with available tools, skills, memory, and then adds the session history (from a `.jsonl` file). this is next passed to the context window gaurd and makes sure if there is enough context space. if the context is almost full, it either compacts the session (summarize the context) or fails gracefully. ## 4. LLM API CALL the LLM call itself streams responses and holds an abstraction over different providers. it can also request extended thinking if the model supports it. ## 5. Agentic Loop if the LLM returns a tool call response, Clawd executes it locally and adds the results to the conversation. This is repeated until the LLM responds with final text or hits max turns (default ~20). this is also where the magic happens: > Computer Use which i will get to. ## 6. Response Path pretty standard. responses get back to you through the channel. the session is also persisted through a basic jsonl with each line a json object of the user message, tool calls, results, resposnes, etc. this is how Clawd remembers (session based memory). this covers the basic architecture. now let's jump on some of the more critical components. # How Clawd Remembers without a proper memory system, an ai assistant is just as good as a goldfish. Clawd handles this through two systems: - Session transcripts in JSONL as mentioned. - Memory files as markdowns in `MEMORY[.]md` or the `memory/` folder. For searching, it uses a hybrid of vector search and keyword matches. This captures the best of both worlds. So searching for "authentication bug" finds both documents mentioning "auth issues" (semantic) and exact phrase (keyword match). for the vector search SQLite is used and for keyword search FTS5 which is also a SQLite extention. the embedding provider is configurable. It also benefits from Smart Synching which triggers when file watcher triggers on file changes. this markdown is generated by the agent itself using a standard 'write' file tool. There's no special memory-write API. the agent simply writes to `memory/*.md`. once a new conversation starts a hok grabs the previous conversation, and writes a summary in markdown. Clawd's memory system is surprisingly simple and very similar to what we have implemented in @CamelAIOrg as workflow memories. No merging of memories, no monthly/weekly memory compressions. This simplicity can be an advantage or a pitfall depending on your perspective, but I'm always in favor of explainable simplicity rather than complex spaghetti. the memory persists forever and old memories have basically equal weight, so we can say there's no forgetting curve. # Clawd's Claws: How it uses your Computer this is one of the MOAT's of Clawd: you give it a computer and let it use. So how does it use the computer? It's basically similar to what you think. Clawd gives the agent significant computer access at your own risks. it uses an exec tool to run shell commands on: • sandbox: the default, wher commands run in a Docker container • directly on host machine • on remote devices Aside from that Clawd also has Filesystem tools (read, write, edit), Browser tool, which is Playwrite-based with semantic snapshots, and Process management (process tool) for background long-term commands, kill processes, etc. ## The Safety (or a lack of none?) Similar to Claude Code there is an allowlist for commands the user would like to approve (allow once, always, deny prompts to the user). safe commands (such as jq, grep, cut, sort, uniq, head, tail, tr, wc) are pre-approved already. dangerous shell constructs are blocked by default. the safety is very similar to what Claude Code has installed. the idea is to have as much autonomy as the user allows. # Browser: Semantic Snapshots the browser tool does not primirily use screenshots, but uses semantic snapshots instead, which is a text-based representation of the page's accessibility tree (ARIA). so an agent would see: This gives away four significant advantages. As you may have guessed, the act of browsing websites is not necessarily a visual task. while a screenshot would have 5 MB of size, a semantic snapshot would have less than 50 KB, and the fraction of the token cost of an image.


Anthropic released a report of the most important ways coding is being transformed in 2026: 1. engineers are becoming orchestrators, not just coders. the role is shifting from code, to managing agents, verifying their outputs, and designing architectures. 2. single agents → multi-agent systems. solving tasks sequentially is turning into teams of agents working in parallel. 3. Agents are moving from minutes-long tasks to days-long autonomous work. 4. AI coding isn’t fully autonomous yet. the benefit is in the increased output volume (more features, more bugs fixed, more experiments). 27% of AI work is tasks that wouldn’t have been done at all otherwise. 5. agentic coding isn’t just about software teams now. legal, sales, marketing, and operations are using agents to build their own tools

you became a programmer to write high-quality code with zero communication skills, but now you must communicate with AI to “solve problems”.

the next time you get rejected after 3 interviews thinking the world doesn't value you enough, remember that the world also believes you can be a $30B AI IDE just so people use you to run Claude Code and Codex extensions. the world isn't fair.

the biggest threat of AI isn’t layoffs, economics, or destroying humans. it’s eliminating the need for painful and critical thinking. banging your head, read docs you hate, spending a week on a bug, it’s all gone, and i too believe there is a downside to that. here’s the deal: acknowledge that whatever you use AI for will most likely slip away from your cognitive grasp over time. the struggle that ai has taken from you was a critical and painful signal that you were actually growing. how are we supposed to learn and grow post-AI? i don’t think there is yet a simple answer to that. maybe for now, everyone can see how they can cope with this. maybe set out a portion of your time AI-free just learning/coding like 5 years ago and accept that you’re doing it slower than sb with AI but you’re actually learning things. what even is learning? are you supposed to *learn* like you needed to do 10 years ago? how are you supposed to be better than the tool you’re leaning on? these are very important questions that need answers. maybe you can think about them too.
