

Andrej Karpathy
Building @EurekaLabsAI. Previously Director of AI @ Tesla, founding team @ OpenAI, CS231n/PhD @ Stanford. I like to train large deep neural nets.
Page 1 • Showing 20 tweets
It is hard to communicate how much programming has changed due to AI in the last 2 months: not gradually and over time in the "progress as usual" way, but specifically this last December. There are a number of asterisks but imo coding agents basically didn’t work before December and basically work since - the models have significantly higher quality, long-term coherence and tenacity and they can power through large and long tasks, well past enough that it is extremely disruptive to the default programming workflow. Just to give an example, over the weekend I was building a local video analysis dashboard for the cameras of my home so I wrote: “Here is the local IP and username/password of my DGX Spark. Log in, set up ssh keys, set up vLLM, download and bench Qwen3-VL, set up a server endpoint to inference videos, a basic web ui dashboard, test everything, set it up with systemd, record memory notes for yourself and write up a markdown report for me”. The agent went off for ~30 minutes, ran into multiple issues, researched solutions online, resolved them one by one, wrote the code, tested it, debugged it, set up the services, and came back with the report and it was just done. I didn’t touch anything. All of this could easily have been a weekend project just 3 months ago but today it’s something you kick off and forget about for 30 minutes. As a result, programming is becoming unrecognizable. You’re not typing computer code into an editor like the way things were since computers were invented, that era is over. You're spinning up AI agents, giving them tasks *in English* and managing and reviewing their work in parallel. The biggest prize is in figuring out how you can keep ascending the layers of abstraction to set up long-running orchestrator Claws with all of the right tools, memory and instructions that productively manage multiple parallel Code instances for you. The leverage achievable via top tier "agentic engineering" feels very high right now. It’s not perfect, it needs high-level direction, judgement, taste, oversight, iteration and hints and ideas. It works a lot better in some scenarios than others (e.g. especially for tasks that are well-specified and where you can verify/test functionality). The key is to build intuition to decompose the task just right to hand off the parts that work and help out around the edges. But imo, this is nowhere near "business as usual" time in software.
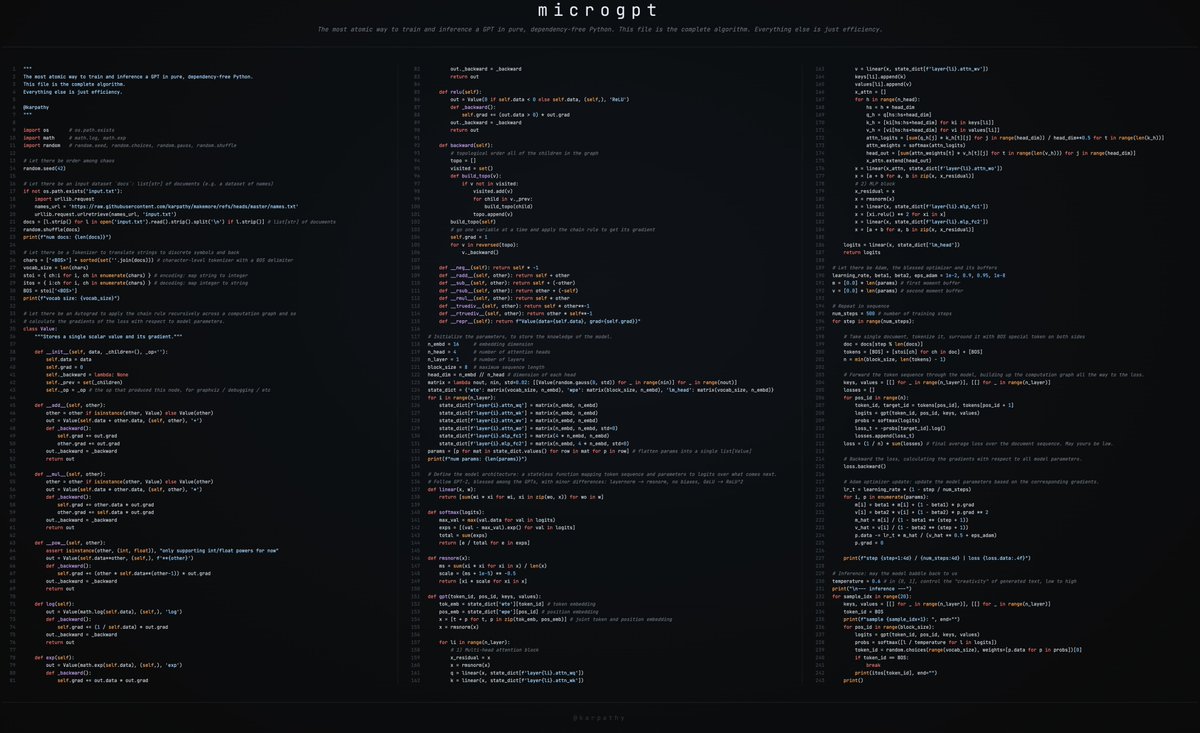
Ok I made a few changes to microgpt because it was still not simple enough. But surely *now* we have the irreducible essence. Here it is on 3 columns 🖼️. nice. https://karpathy.ai/microgpt.html wait...
Anyone else approved for a loan every single day 20 times or so? Overcome with joy, really

I've never felt this much behind as a programmer. The profession is being dramatically refactored as the bits contributed by the programmer are increasingly sparse and between. I have a sense that I could be 10X more powerful if I just properly string together what has become available over the last ~year and a failure to claim the boost feels decidedly like skill issue. There's a new programmable layer of abstraction to master (in addition to the usual layers below) involving agents, subagents, their prompts, contexts, memory, modes, permissions, tools, plugins, skills, hooks, MCP, LSP, slash commands, workflows, IDE integrations, and a need to build an all-encompassing mental model for strengths and pitfalls of fundamentally stochastic, fallible, unintelligible and changing entities suddenly intermingled with what used to be good old fashioned engineering. Clearly some powerful alien tool was handed around except it comes with no manual and everyone has to figure out how to hold it and operate it, while the resulting magnitude 9 earthquake is rocking the profession. Roll up your sleeves to not fall behind.
A number of people are talking about implications of AI to schools. I spoke about some of my thoughts to a school board earlier, some highlights: 1. You will never be able to detect the use of AI in homework. Full stop. All "detectors" of AI imo don't really work, can be defeated in various ways, and are in principle doomed to fail. You have to assume that any work done outside classroom has used AI. 2. Therefore, the majority of grading has to shift to in-class work (instead of at-home assignments), in settings where teachers can physically monitor students. The students remain motivated to learn how to solve problems without AI because they know they will be evaluated without it in class later. 3. We want students to be able to use AI, it is here to stay and it is extremely powerful, but we also don't want students to be naked in the world without it. Using the calculator as an example of a historically disruptive technology, school teaches you how to do all the basic math & arithmetic so that you can in principle do it by hand, even if calculators are pervasive and greatly speed up work in practical settings. In addition, you understand what it's doing for you, so should it give you a wrong answer (e.g. you mistyped "prompt"), you should be able to notice it, gut check it, verify it in some other way, etc. The verification ability is especially important in the case of AI, which is presently a lot more fallible in a great variety of ways compared to calculators. 4. A lot of the evaluation settings remain at teacher's discretion and involve a creative design space of no tools, cheatsheets, open book, provided AI responses, direct internet/AI access, etc. TLDR the goal is that the students are proficient in the use of AI, but can also exist without it, and imo the only way to get there is to flip classes around and move the majority of testing to in class settings.

I am unreasonably excited about self-driving. It will be the first technology in many decades to visibly terraform outdoor physical spaces and way of life. Less parked cars. Less parking lots. Much greater safety for people in and out of cars. Less noise pollution. More space reclaimed for humans. Human brain cycles and attention capital freed up from “lane following” to other pursuits. Cheaper, faster, programmable delivery of physical items and goods. It won’t happen overnight but there will be the era before and the era after.
TV in the 90s: you turn it on, you watch. TV 2025: - turn on, wait for it to load - popup: TV wants to update, 1.5GB. No. - scroll sideways, find prime video app or etc - popup: now app wants to update, 500MB. No!! - App launching... App loading… - select account screen -
Bought a new Mac mini to properly tinker with claws over the weekend. The apple store person told me they are selling like hotcakes and everyone is confused :) I'm definitely a bit sus'd to run OpenClaw specifically - giving my private data/keys to 400K lines of vibe coded monster that is being actively attacked at scale is not very appealing at all. Already seeing reports of exposed instances, RCE vulnerabilities, supply chain poisoning, malicious or compromised skills in the registry, it feels like a complete wild west and a security nightmare. But I do love the concept and I think that just like LLM agents were a new layer on top of LLMs, Claws are now a new layer on top of LLM agents, taking the orchestration, scheduling, context, tool calls and a kind of persistence to a next level. Looking around, and given that the high level idea is clear, there are a lot of smaller Claws starting to pop out. For example, on a quick skim NanoClaw looks really interesting in that the core engine is ~4000 lines of code (fits into both my head and that of AI agents, so it feels manageable, auditable, flexible, etc.) and runs everything in containers by default. I also love their approach to configurability - it's not done via config files it's done via skills! For example, /add-telegram instructs your AI agent how to modify the actual code to integrate Telegram. I haven't come across this yet and it slightly blew my mind earlier today as a new, AI-enabled approach to preventing config mess and if-then-else monsters. Basically - the implied new meta is to write the most maximally forkable repo and then have skills that fork it into any desired more exotic configuration. Very cool. Anyway there are many others - e.g. nanobot, zeroclaw, ironclaw, picoclaw (lol @ prefixes). There are also cloud-hosted alternatives but tbh I don't love these because it feels much harder to tinker with. In particular, local setup allows easy connection to home automation gadgets on the local network. And I don't know, there is something aesthetically pleasing about there being a physical device 'possessed' by a little ghost of a personal digital house elf. Not 100% sure what my setup ends up looking like just yet but Claws are an awesome, exciting new layer of the AI stack.
New art project. Train and inference GPT in 243 lines of pure, dependency-free Python. This is the *full* algorithmic content of what is needed. Everything else is just for efficiency. I cannot simplify this any further. https://gist.github.com/karpathy/8627fe0…

microgpt
A few random notes from claude coding quite a bit last few weeks. Coding workflow. Given the latest lift in LLM coding capability, like many others I rapidly went from about 80% manual+autocomplete coding and 20% agents in November to 80% agent coding and 20% edits+touchups in December. i.e. I really am mostly programming in English now, a bit sheepishly telling the LLM what code to write... in words. It hurts the ego a bit but the power to operate over software in large "code actions" is just too net useful, especially once you adapt to it, configure it, learn to use it, and wrap your head around what it can and cannot do. This is easily the biggest change to my basic coding workflow in ~2 decades of programming and it happened over the course of a few weeks. I'd expect something similar to be happening to well into double digit percent of engineers out there, while the awareness of it in the general population feels well into low single digit percent. IDEs/agent swarms/fallability. Both the "no need for IDE anymore" hype and the "agent swarm" hype is imo too much for right now. The models definitely still make mistakes and if you have any code you actually care about I would watch them like a hawk, in a nice large IDE on the side. The mistakes have changed a lot - they are not simple syntax errors anymore, they are subtle conceptual errors that a slightly sloppy, hasty junior dev might do. The most common category is that the models make wrong assumptions on your behalf and just run along with them without checking. They also don't manage their confusion, they don't seek clarifications, they don't surface inconsistencies, they don't present tradeoffs, they don't push back when they should, and they are still a little too sycophantic. Things get better in plan mode, but there is some need for a lightweight inline plan mode. They also really like to overcomplicate code and APIs, they bloat abstractions, they don't clean up dead code after themselves, etc. They will implement an inefficient, bloated, brittle construction over 1000 lines of code and it's up to you to be like "umm couldn't you just do this instead?" and they will be like "of course!" and immediately cut it down to 100 lines. They still sometimes change/remove comments and code they don't like or don't sufficiently understand as side effects, even if it is orthogonal to the task at hand. All of this happens despite a few simple attempts to fix it via instructions in CLAUDE . md. Despite all these issues, it is still a net huge improvement and it's very difficult to imagine going back to manual coding. TLDR everyone has their developing flow, my current is a small few CC sessions on the left in ghostty windows/tabs and an IDE on the right for viewing the code + manual edits. Tenacity. It's so interesting to watch an agent relentlessly work at something. They never get tired, they never get demoralized, they just keep going and trying things where a person would have given up long ago to fight another day. It's a "feel the AGI" moment to watch it struggle with something for a long time just to come out victorious 30 minutes later. You realize that stamina is a core bottleneck to work and that with LLMs in hand it has been dramatically increased. Speedups. It's not clear how to measure the "speedup" of LLM assistance. Certainly I feel net way faster at what I was going to do, but the main effect is that I do a lot more than I was going to do because 1) I can code up all kinds of things that just wouldn't have been worth coding before and 2) I can approach code that I couldn't work on before because of knowledge/skill issue. So certainly it's speedup, but it's possibly a lot more an expansion. Leverage. LLMs are exceptionally good at looping until they meet specific goals and this is where most of the "feel the AGI" magic is to be found. Don't tell it what to do, give it success criteria and watch it go. Get it to write tests first and then pass them. Put it in the loop with a browser MCP. Write the naive algorithm that is very likely correct first, then ask it to optimize it while preserving correctness. Change your approach from imperative to declarative to get the agents looping longer and gain leverage. Fun. I didn't anticipate that with agents programming feels *more* fun because a lot of the fill in the blanks drudgery is removed and what remains is the creative part. I also feel less blocked/stuck (which is not fun) and I experience a lot more courage because there's almost always a way to work hand in hand with it to make some positive progress. I have seen the opposite sentiment from other people too; LLM coding will split up engineers based on those who primarily liked coding and those who primarily liked building. Atrophy. I've already noticed that I am slowly starting to atrophy my ability to write code manually. Generation (writing code) and discrimination (reading code) are different capabilities in the brain. Largely due to all the little mostly syntactic details involved in programming, you can review code just fine even if you struggle to write it. Slopacolypse. I am bracing for 2026 as the year of the slopacolypse across all of github, substack, arxiv, X/instagram, and generally all digital media. We're also going to see a lot more AI hype productivity theater (is that even possible?), on the side of actual, real improvements. Questions. A few of the questions on my mind: - What happens to the "10X engineer" - the ratio of productivity between the mean and the max engineer? It's quite possible that this grows *a lot*. - Armed with LLMs, do generalists increasingly outperform specialists? LLMs are a lot better at fill in the blanks (the micro) than grand strategy (the macro). - What does LLM coding feel like in the future? Is it like playing StarCraft? Playing Factorio? Playing music? - How much of society is bottlenecked by digital knowledge work? TLDR Where does this leave us? LLM agent capabilities (Claude & Codex especially) have crossed some kind of threshold of coherence around December 2025 and caused a phase shift in software engineering and closely related. The intelligence part suddenly feels quite a bit ahead of all the rest of it - integrations (tools, knowledge), the necessity for new organizational workflows, processes, diffusion more generally. 2026 is going to be a high energy year as the industry metabolizes the new capability.
I love the expression “food for thought” as a concrete, mysterious cognitive capability humans experience but LLMs have no equivalent for. Definition: “something worth thinking about or considering, like a mental meal that nourishes your mind with ideas, insights, or issues that require deeper reflection. It's used for topics that challenge your perspective, offer new understanding, or make you ponder important questions, acting as intellectual stimulation.” So in LLM speak it’s a sequence of tokens such that when used as prompt for chain of thought, the samples are rewarding to attend over, via some yet undiscovered intrinsic reward function. Obsessed with what form it takes. Food for thought.
I’m starting to get into a habit of reading everything (blogs, articles, book chapters,…) with LLMs. Usually pass 1 is manual, then pass 2 “explain/summarize”, pass 3 Q&A. I usually end up with a better/deeper understanding than if I moved on. Growing to among top use cases. On the flip side, if you’re a writer trying to explain/communicate something, we may increasingly see less of a mindset of “I’m writing this for another human” and more “I’m writing this for an LLM”. Because once an LLM “gets it”, it can then target, personalize and serve the idea to its user.
Tbh I never really got 10+ year timelines. To me they just mean that we need 1 or more breakthroughs and we just assume a decade is enough to find them
Excited to release new repo: nanochat! (it's among the most unhinged I've written). Unlike my earlier similar repo nanoGPT which only covered pretraining, nanochat is a minimal, from scratch, full-stack training/inference pipeline of a simple ChatGPT clone in a single, dependency-minimal codebase. You boot up a cloud GPU box, run a single script and in as little as 4 hours later you can talk to your own LLM in a ChatGPT-like web UI. It weighs ~8,000 lines of imo quite clean code to: - Train the tokenizer using a new Rust implementation - Pretrain a Transformer LLM on FineWeb, evaluate CORE score across a number of metrics - Midtrain on user-assistant conversations from SmolTalk, multiple choice questions, tool use. - SFT, evaluate the chat model on world knowledge multiple choice (ARC-E/C, MMLU), math (GSM8K), code (HumanEval) - RL the model optionally on GSM8K with "GRPO" - Efficient inference the model in an Engine with KV cache, simple prefill/decode, tool use (Python interpreter in a lightweight sandbox), talk to it over CLI or ChatGPT-like WebUI. - Write a single markdown report card, summarizing and gamifying the whole thing. Even for as low as ~$100 in cost (~4 hours on an 8XH100 node), you can train a little ChatGPT clone that you can kind of talk to, and which can write stories/poems, answer simple questions. About ~12 hours surpasses GPT-2 CORE metric. As you further scale up towards ~$1000 (~41.6 hours of training), it quickly becomes a lot more coherent and can solve simple math/code problems and take multiple choice tests. E.g. a depth 30 model trained for 24 hours (this is about equal to FLOPs of GPT-3 Small 125M and 1/1000th of GPT-3) gets into 40s on MMLU and 70s on ARC-Easy, 20s on GSM8K, etc. My goal is to get the full "strong baseline" stack into one cohesive, minimal, readable, hackable, maximally forkable repo. nanochat will be the capstone project of LLM101n (which is still being developed). I think it also has potential to grow into a research harness, or a benchmark, similar to nanoGPT before it. It is by no means finished, tuned or optimized (actually I think there's likely quite a bit of low-hanging fruit), but I think it's at a place where the overall skeleton is ok enough that it can go up on GitHub where all the parts of it can be improved. Link to repo and a detailed walkthrough of the nanochat speedrun is in the reply.
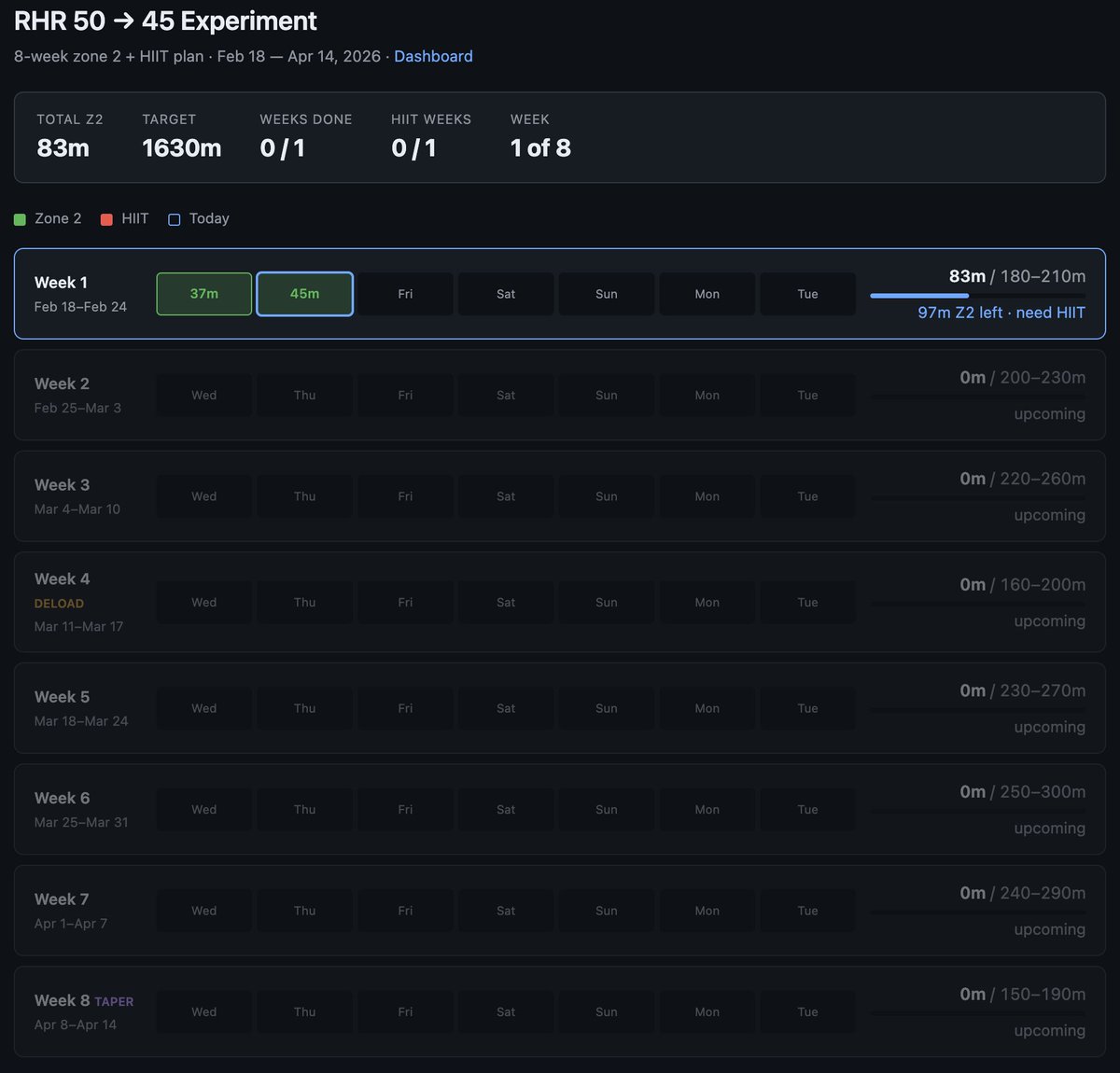
Very interested in what the coming era of highly bespoke software might look like. Example from this morning - I've become a bit loosy goosy with my cardio recently so I decided to do a more srs, regimented experiment to try to lower my Resting Heart Rate from 50 -> 45, over experiment duration of 8 weeks. The primary way to do this is to aspire to a certain sum total minute goals in Zone 2 cardio and 1 HIIT/week. 1 hour later I vibe coded this super custom dashboard for this very specific experiment that shows me how I'm tracking. Claude had to reverse engineer the Woodway treadmill cloud API to pull raw data, process, filter, debug it and create a web UI frontend to track the experiment. It wasn't a fully smooth experience and I had to notice and ask to fix bugs e.g. it screwed up metric vs. imperial system units and it screwed up on the calendar matching up days to dates etc. But I still feel like the overall direction is clear: 1) There will never be (and shouldn't be) a specific app on the app store for this kind of thing. I shouldn't have to look for, download and use some kind of a "Cardio experiment tracker", when this thing is ~300 lines of code that an LLM agent will give you in seconds. The idea of an "app store" of a long tail of discrete set of apps you choose from feels somehow wrong and outdated when LLM agents can improvise the app on the spot and just for you. 2) Second, the industry has to reconfigure into a set of services of sensors and actuators with agent native ergonomics. My Woodway treadmill is a sensor - it turns physical state into digital knowledge. It shouldn't maintain some human-readable frontend and my LLM agent shouldn't have to reverse engineer it, it should be an API/CLI easily usable by my agent. I'm a little bit disappointed (and my timelines are correspondingly slower) with how slowly this progression is happening in the industry overall. 99% of products/services still don't have an AI-native CLI yet. 99% of products/services maintain .html/.css docs like I won't immediately look for how to copy paste the whole thing to my agent to get something done. They give you a list of instructions on a webpage to open this or that url and click here or there to do a thing. In 2026. What am I a computer? You do it. Or have my agent do it. So anyway today I am impressed that this random thing took 1 hour (it would have been ~10 hours 2 years ago). But what excites me more is thinking through how this really should have been 1 minute tops. What has to be in place so that it would be 1 minute? So that I could simply say "Hi can you help me track my cardio over the next 8 weeks", and after a very brief Q&A the app would be up. The AI would already have a lot personal context, it would gather the extra needed data, it would reference and search related skill libraries, and maintain all my little apps/automations. TLDR the "app store" of a set of discrete apps that you choose from is an increasingly outdated concept all by itself. The future are services of AI-native sensors & actuators orchestrated via LLM glue into highly custom, ephemeral apps. It's just not here yet.
On DeepWiki and increasing malleability of software. This starts as partially a post on appreciation to DeepWiki, which I routinely find very useful and I think more people would find useful to know about. I went through a few iterations of use: Their first feature was that it auto-builds wiki pages for github repos (e.g. nanochat here) with quick Q&A: https://deepwiki.com/karpathy/nanochat Just swap "github" to "deepwiki" in the URL for any repo and you can instantly Q&A against it. For example, yesterday I was curious about "how does torchao implement fp8 training?". I find that in *many* cases, library docs can be spotty and outdated and bad, but directly asking questions to the code via DeepWiki works very well. The code is the source of truth and LLMs are increasingly able to understand it. But then I realized that in many cases it's even a lot more powerful not being the direct (human) consumer of this information/functionality, but giving your agent access to DeepWiki via MCP. So e.g. yesterday I faced some annoyances with using torchao library for fp8 training and I had the suspicion that the whole thing really shouldn't be that complicated (wait shouldn't this be a Function like Linear except with a few extra casts and 3 calls to torch._scaled_mm?) so I tried: "Use DeepWiki MCP and Github CLI to look at how torchao implements fp8 training. Is it possible to 'rip out' the functionality? Implement nanochat/fp8.py that has identical API but is fully self-contained" Claude went off for 5 minutes and came back with 150 lines of clean code that worked out of the box, with tests proving equivalent results, which allowed me to delete torchao as repo dependency, and for some reason I still don't fully understand (I think it has to do with internals of torch compile) - this simple version runs 3% faster. The agent also found a lot of tiny implementation details that actually do matter, that I may have naively missed otherwise and that would have been very hard for maintainers to keep docs about. Tricks around numerics, dtypes, autocast, meta device, torch compile interactions so I learned a lot from the process too. So this is now the default fp8 training implementation for nanochat https://github.com/karpathy/nanochat/com… Anyway TLDR I find this combo of DeepWiki MCP + GitHub CLI is quite powerful to "rip out" any specific functionality from any github repo and target it for the very specific use case that you have in mind, and it actually kind of works now in some cases. Maybe you don't download, configure and take dependency on a giant monolithic library, maybe you point your agent at it and rip out the exact part you need. Maybe this informs how we write software more generally to actively encourage this workflow - e.g. building more "bacterial code", code that is less tangled, more self-contained, more dependency-free, more stateless, much easier to rip out from the repo (https://x.com/karpathy/status/1941616674…) There's obvious downsides and risks to this, but it is fundamentally a new option that was not possible or economical before (it would have cost too much time) but now with agents, it is. Software might become a lot more fluid and malleable. "Libraries are over, LLMs are the new compiler" :). And does your project really need its 100MB of dependencies?

karpathy/nanochat | DeepWiki
The majority of the ruff ruff is people who look at the current point and people who look at the current slope.
Gemini Nano Banana Pro can solve exam questions *in* the exam page image. With doodles, diagrams, all that. ChatGPT thinks these solutions are all correct except Se_2P_2 should be "diselenium diphosphide" and a spelling mistake (should be "thiocyanic acid" not "thoicyanic") :O
Sharing an interesting recent conversation on AI's impact on the economy. AI has been compared to various historical precedents: electricity, industrial revolution, etc., I think the strongest analogy is that of AI as a new computing paradigm (Software 2.0) because both are fundamentally about the automation of digital information processing. If you were to forecast the impact of computing on the job market in ~1980s, the most predictive feature of a task/job you'd look at is to what extent the algorithm of it is fixed, i.e. are you just mechanically transforming information according to rote, easy to specify rules (e.g. typing, bookkeeping, human calculators, etc.)? Back then, this was the class of programs that the computing capability of that era allowed us to write (by hand, manually). With AI now, we are able to write new programs that we could never hope to write by hand before. We do it by specifying objectives (e.g. classification accuracy, reward functions), and we search the program space via gradient descent to find neural networks that work well against that objective. This is my Software 2.0 blog post from a while ago. In this new programming paradigm then, the new most predictive feature to look at is verifiability. If a task/job is verifiable, then it is optimizable directly or via reinforcement learning, and a neural net can be trained to work extremely well. It's about to what extent an AI can "practice" something. The environment has to be resettable (you can start a new attempt), efficient (a lot attempts can be made), and rewardable (there is some automated process to reward any specific attempt that was made). The more a task/job is verifiable, the more amenable it is to automation in the new programming paradigm. If it is not verifiable, it has to fall out from neural net magic of generalization fingers crossed, or via weaker means like imitation. This is what's driving the "jagged" frontier of progress in LLMs. Tasks that are verifiable progress rapidly, including possibly beyond the ability of top experts (e.g. math, code, amount of time spent watching videos, anything that looks like puzzles with correct answers), while many others lag by comparison (creative, strategic, tasks that combine real-world knowledge, state, context and common sense). Software 1.0 easily automates what you can specify. Software 2.0 easily automates what you can verify.
My pleasure to come on Dwarkesh last week, I thought the questions and conversation were really good. I re-watched the pod just now too. First of all, yes I know, and I'm sorry that I speak so fast :). It's to my detriment because sometimes my speaking thread out-executes my thinking thread, so I think I botched a few explanations due to that, and sometimes I was also nervous that I'm going too much on a tangent or too deep into something relatively spurious. Anyway, a few notes/pointers: AGI timelines. My comments on AGI timelines looks to be the most trending part of the early response. This is the "decade of agents" is a reference to this earlier tweet https:// x.com/karpathy/statu s/1882544526033924438 … Basically my AI timelines are about 5-10X pessimistic w.r.t. what you'll find in your neighborhood SF AI house party or on your twitter timeline, but still quite optimistic w.r.t. a rising tide of AI deniers and skeptics. The apparent conflict is not: imo we simultaneously 1) saw a huge amount of progress in recent years with LLMs while 2) there is still a lot of work remaining (grunt work, integration work, sensors and actuators to the physical world, societal work, safety and security work (jailbreaks, poisoning, etc.)) and also research to get done before we have an entity that you'd prefer to hire over a person for an arbitrary job in the world. I think that overall, 10 years should otherwise be a very bullish timeline for AGI, it's only in contrast to present hype that it doesn't feel that way. Animals vs Ghosts. My earlier writeup on Sutton's podcast https:// x.com/karpathy/statu s/1973435013875314729 … . I am suspicious that there is a single simple algorithm you can let loose on the world and it learns everything from scratch. If someone builds such a thing, I will be wrong and it will be the most incredible breakthrough in AI. In my mind, animals are not an example of this at all - they are prepackaged with a ton of intelligence by evolution and the learning they do is quite minimal overall (example: Zebra at birth). Putting our engineering hats on, we're not going to redo evolution. But with LLMs we have stumbled by an alternative approach to "prepackage" a ton of intelligence in a neural network - not by evolution, but by predicting the next token over the internet. This approach leads to a different kind of entity in the intelligence space. Distinct from animals, more like ghosts or spirits. But we can (and should) make them more animal like over time and in some ways that's what a lot of frontier work is about. On RL. I've critiqued RL a few times already, e.g. https:// x.com/karpathy/statu s/1944435412489171119 … . First, you're "sucking supervision through a straw", so I think the signal/flop is very bad. RL is also very noisy because a completion might have lots of errors that might get encourages (if you happen to stumble to the right answer), and conversely brilliant insight tokens that might get discouraged (if you happen to screw up later). Process supervision and LLM judges have issues too. I think we'll see alternative learning paradigms. I am long "agentic interaction" but short "reinforcement learning" https:// x.com/karpathy/statu s/1960803117689397543 …. I've seen a number of papers pop up recently that are imo barking up the right tree along the lines of what I called "system prompt learning" https:// x.com/karpathy/statu s/1921368644069765486 … , but I think there is also a gap between ideas on arxiv and actual, at scale implementation at an LLM frontier lab that works in a general way. I am overall quite optimistic that we'll see good progress on this dimension of remaining work quite soon, and e.g. I'd even say ChatGPT memory and so on are primordial deployed examples of new learning paradigms. Cognitive core. My earlier post on "cognitive core": https:// x.com/karpathy/statu s/1938626382248149433 … , the idea of stripping down LLMs, of making it harder for them to memorize, or actively stripping away their memory, to make them better at generalization. Otherwise they lean too hard on what they've memorized. Humans can't memorize so easily, which now looks more like a feature than a bug by contrast. Maybe the inability to memorize is a kind of regularization. Also my post from a while back on how the trend in model size is "backwards" and why "the models have to first get larger before they can get smaller" https:// x.com/karpathy/statu s/1814038096218083497 … Time travel to Yann LeCun 1989. This is the post that I did a very hasty/bad job of describing on the pod: https:// x.com/karpathy/statu s/1503394811188973569 … . Basically - how much could you improve Yann LeCun's results with the knowledge of 33 years of algorithmic progress? How constrained were the results by each of algorithms, data, and compute? Case study there of. nanochat. My end-to-end implementation of the ChatGPT training/inference pipeline (the bare essentials) https:// x.com/karpathy/statu s/1977755427569111362 … On LLM agents. My critique of the industry is more in overshooting the tooling w.r.t. present capability. I live in what I view as an intermediate world where I want to collaborate with LLMs and where our pros/cons are matched up. The industry lives in a future where fully autonomous entities collaborate in parallel to write all the code and humans are useless. For example, I don't want an Agent that goes off for 20 minutes and comes back with 1,000 lines of code. I certainly don't feel ready to supervise a team of 10 of them. I'd like to go in chunks that I can keep in my head, where an LLM explains the code that it is writing. I'd like it to prove to me that what it did is correct, I want it to pull the API docs and show me that it used things correctly. I want it to make fewer assumptions and ask/collaborate with me when not sure about something. I want to learn along the way and become better as a programmer, not just get served mountains of code that I'm told works. I just think the tools should be more realistic w.r.t. their capability and how they fit into the industry today, and I fear that if this isn't done well we might end up with mountains of slop accumulating across software, and an increase in vulnerabilities, security breaches and etc. https:// x.com/karpathy/statu s/1915581920022585597 … Job automation. How the radiologists are doing great https:// x.com/karpathy/statu s/1971220449515516391 … and what jobs are more susceptible to automation and why. Physics. Children should learn physics in early education not because they go on to do physics, but because it is the subject that best boots up a brain. Physicists are the intellectual embryonic stem cell https:// x.com/karpathy/statu s/1929699637063307286 … I have a longer post that has been half-written in my drafts for ~year, which I hope to finish soon. Thanks again Dwarkesh for having me over!