Data science
Congrats to @encord_team on their $60M Series C! Encord is building the AI-native data layer powering physical AI, helping 300+ teams manage and align massive volumes of multimodal data as robots and autonomous systems move into real-world deployment.


gemini 3.1 pro dropped and nobody's talking about the real play here... it's not the benchmarks or the reasoning scores but what happens when you pair it with NotebookLM here's how i use it for literally everything i work on: 1. open NotebookLM, run Deep Research on your topic 2. it pulls hundreds of sources from across the web automatically 3. review everything, cut the garbage, keep only what's good 4. now you have a curated knowledge base grounded in real sources this is where it gets interesting... > import that notebook directly into Gemini > build a Gem with your notebook as context > now every prompt you write is backed by YOUR research, YOUR sources this thing was built to process massive context... 1M tokens, entire codebases, hundreds of documents at once if you're prompting it with zero context you're wasting the most powerful part of the model notebooks are the knowledge layer and gemini is the reasoning engine stack them together and you have the best system to process large context files
Cascade (@cascade_intel) builds custom evaluation infrastructure that learns from real production workflows. It helps teams deploy agents that improve on their data for their use cases - making them safer and more reliable. Congrats on the launch, @adam_alsayyad and Haluk! https://ycombinator.com/launches/PXX-cas…

Which model do you actually use for code every day?
Codex weekly users have more than tripled since the beginning of the year!
What is a non-obvious, meaningful way that you've... 1. Automated a boring part of your daily knowledge work 2. Found an insight from messy or scattered data 3. Stumbled onto something joyful ... due to AI assistants, agents, OpenClaw, et al.? (slop bot replies pls spare me)

We’ve identified industrial-scale distillation attacks on our models by DeepSeek, Moonshot AI, and MiniMax. These labs created over 24,000 fraudulent accounts and generated over 16 million exchanges with Claude, extracting its capabilities to train and improve their own models.
Vibe Code Enterprise Data Apps with Replit + Databricks https://x.com/i/broadcasts/1kJzDMDdOoWKv
.@strandaibio builds foundation models to fill in missing patient data. They predict unmeasured biological modalities from existing ones, turning sparse clinical trial datasets into complete multimodal profiles. Congrats on the launch, @_odedf and @moremelessyue! https://ycombinator.com/launches/PXW-str…

John on $NVDA: Even if TSMC does scale up magically, or they figure out how to build another fab, or Arizona increases capacity, you could still wind up in a weird scenario: Nvidia has the chips, they're ready to sell them, the hyperscalers want to buy them, and the AI labs want to run inference on them, but there's just not enough energy. The question is, when does the chip bottleneck shift to the energy bottleneck? That could be part of what is worrying people.


Node got 50% more memory efficient with a simple trick. This was such a fun deep dive in Node internals

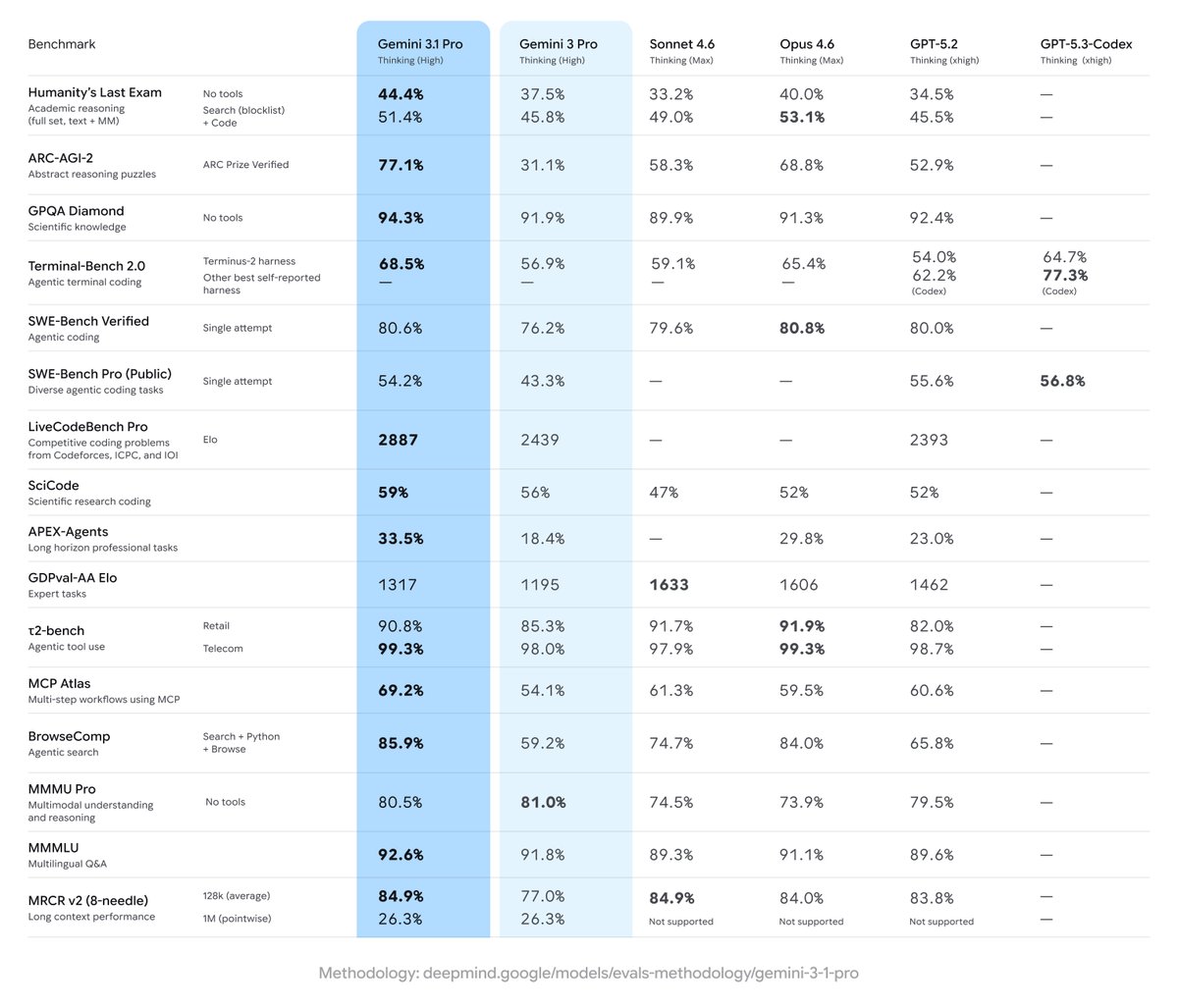
Introducing Gemini 3.1 Pro, our new SOTA model across most reasoning, coding, and stem use cases!
BREAKING: Google Research just dropped the textbook killer. Its called "Learn Your Way" and it uses LearnLM to transform any PDF into 5 personalized learning formats. Students using it scored 78% vs 67% on retention tests. The education revolution is here.

The compute bottleneck is massively under appreciated. I would guess the gap between supply and demand is growing single digit % every day.