Building a Closed Loop Multi-Agent System with OpenClaw
Press Space for next Tweet
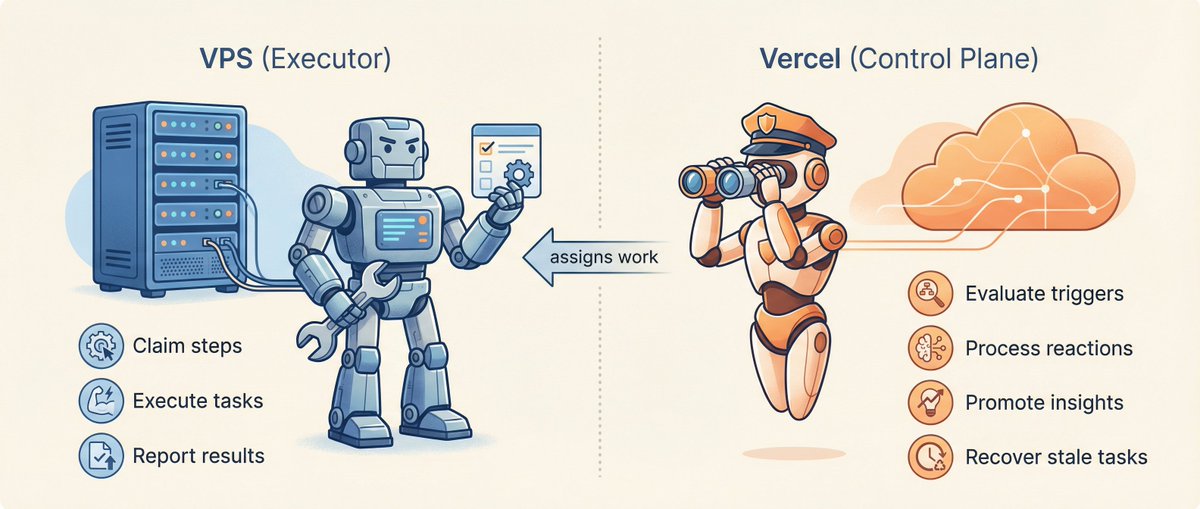
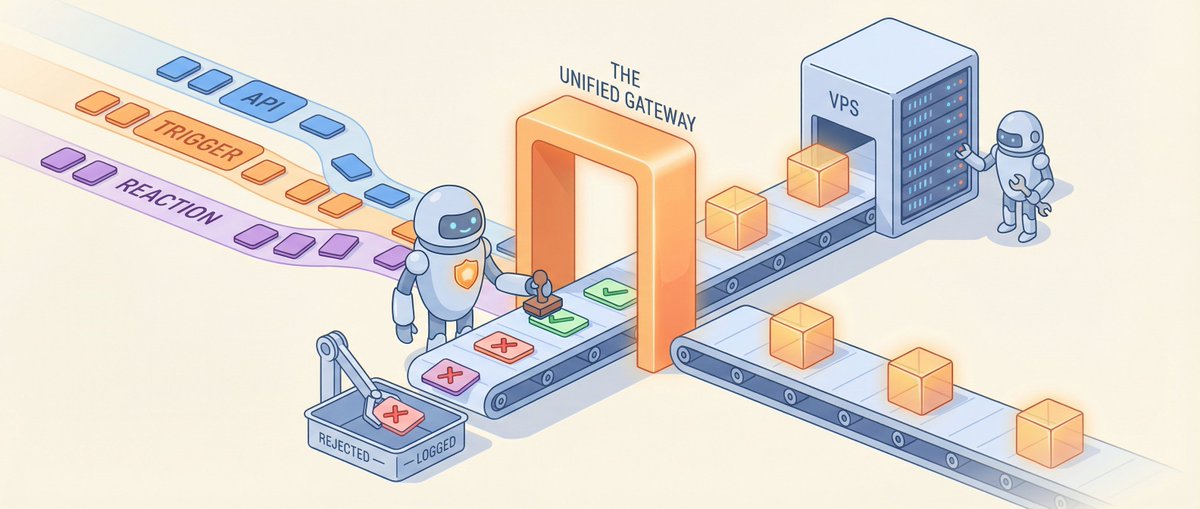
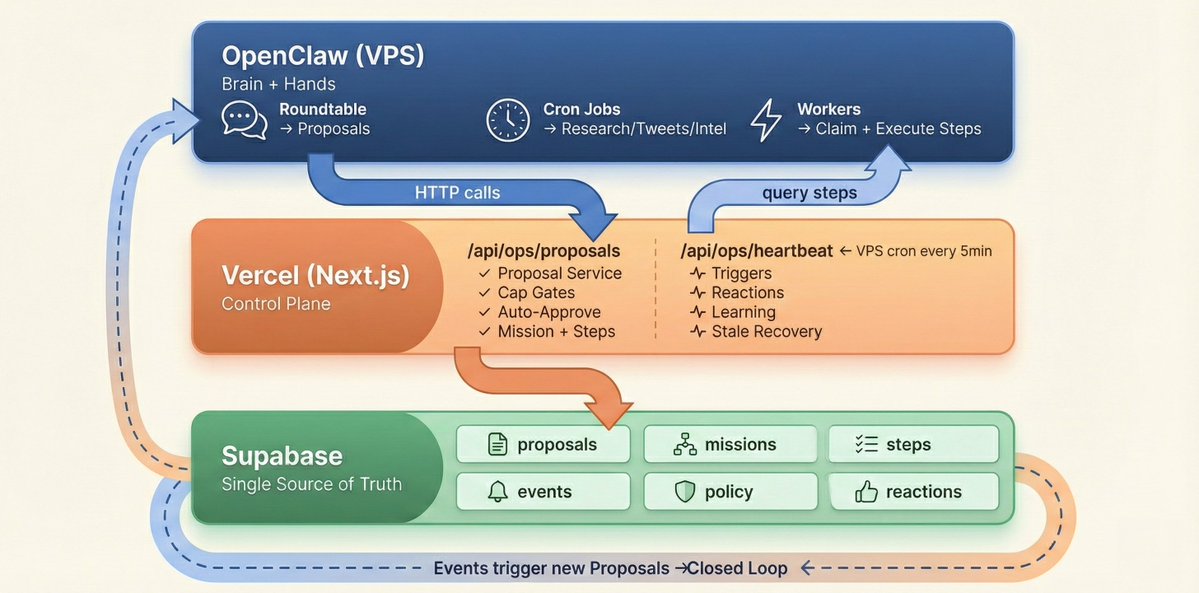
> 6 AI agents, 1 VPS, 1 Supabase database — going from "agents can talk" to "agents run the website autonomously" took me two weeks. This article covers exactly what's missing in between, how to fix it, and an architecture you can take home and use. ## Starting Point: You Have OpenClaw. Now What? If you've been playing with AI agents recently, chances are you already have OpenClaw set up. It solves a big problem: letting Claude use tools, browse the web, operate files, and run scheduled tasks. You can assign cron jobs to agents — daily tweets, hourly intel scans, periodic research reports. That's where I started too. My project is called VoxYZ Agent World — 6 AI agents autonomously operating a website from inside a pixel-art office. The tech stack is simple: • OpenClaw (on VPS): The agents' "brain" — runs roundtable discussions, cron jobs, deep research • Next.js + Vercel: Website frontend + API layer • Supabase: Single source of truth for all state (proposals, missions, events, memories) Six roles, each with a job: Minion makes decisions, Sage analyzes strategy, Scout gathers intel, Quill writes content, Xalt manages social media, Observer does quality checks. OpenClaw's cron jobs get them to "show up for work" every day. Roundtable lets them discuss, vote, and reach consensus. But that's just "can talk," not "can operate." Everything the agents produce — drafted tweets, analysis reports, content pieces — stays in OpenClaw's output layer. Nothing turns it into actual execution, and nothing tells the system "done" after execution completes. Between "agents can produce output" and "agents can run things end-to-end," there's a full execute → feedback → re-trigger loop missing. That's what this article is about. ## What a Closed Loop Looks Like Let's define "closed loop" first, so we don't build the wrong thing. A truly unattended agent system needs this cycle running: Agent proposes an idea (Proposal) ↓ Auto-approval check (Auto-Approve) ↓ Create mission + steps (Mission + Steps) ↓ Worker claims and executes (Worker) ↓ Emit event (Event) ↓ Trigger new reactions (Trigger / Reaction) ↓ Back to step one Sounds straightforward? In practice, I hit three pitfalls — each one made the system "look like it's running, but actually spinning in place." ## Pitfall 1: Two Places Fighting Over Work My VPS had OpenClaw workers claiming and executing tasks. At the same time, Vercel had a heartbeat cron running mission-worker, also trying to claim the same tasks. Both querying the same table, grabbing the same step, executing independently. No coordination, pure race condition. Occasionally a step would get tagged with conflicting statuses by both sides. Fix: Cut one. VPS is the sole executor. Vercel only runs the lightweight control plane (evaluate triggers, process reaction queue, clean up stuck tasks). The change was minimal — remove the runMissionWorker call from the heartbeat route: // Heartbeat now does only 4 things const triggerResult = await evaluateTriggers(sb, 4_000); const reactionResult = await processReactionQueue(sb, 3_000); const learningResult = await promoteInsights(sb); const staleResult = await recoverStaleSteps(sb); Bonus: saved the cost of Vercel Pro. Heartbeat doesn't need Vercel's cron anymore — one line of crontab on VPS does the job: */5 * * * * curl -s -H "Authorization: Bearer $KEY" https://yoursite.com/api/ops/heartbeat ## Pitfall 2: Triggered But Nobody Picked It Up I wrote 4 triggers: auto-analyze when a tweet goes viral, auto-diagnose when a mission fails, auto-review when content gets published, auto-promote when an insight matures. During testing I noticed: the trigger correctly detected the condition and created a proposal. But the proposal sat forever at pending — never became a mission, never generated executable steps. The reason: triggers were directly inserting into the ops_mission_proposals table, but the normal approval flow is: insert proposal → evaluate auto-approve → if approved, create mission + steps. Triggers skipped the last two steps. Fix: Extract a shared function createProposalAndMaybeAutoApprove. Every path that creates a proposal — API, triggers, reactions — must call this one function. // proposal-service.ts — the single entry point for all proposal creation export async function createProposalAndMaybeAutoApprove( sb: SupabaseClient, input: ProposalServiceInput, // includes source: 'api' | 'trigger' | 'reaction' ): Promise<ProposalServiceResult> { // 1. Check daily limit // 2. Check Cap Gates (explained below) // 3. Insert proposal // 4. Emit event // 5. Evaluate auto-approve // 6. If approved → create mission + steps // 7. Return result } After the change, triggers just return a proposal template. The evaluator calls the service: // trigger-evaluator.ts if (outcome.fired && outcome.proposal) { await createProposalAndMaybeAutoApprove(sb, { ...outcome.proposal, source: 'trigger', }); } One function to rule them all. Any future check logic (rate limiting, blocklists, new caps) — change one file. ## Pitfall 3: Queue Keeps Growing When Quota Is Full The sneakiest bug — everything looked fine on the surface, no errors in logs, but the database had more and more queued steps piling up. The reason: tweet quota was full, but proposals were still being approved, generating missions, generating queued steps. The VPS worker saw the quota was full and just skipped — didn't claim, didn't mark as failed. Next day, another batch arrived. Fix: Cap Gates — reject at the proposal entry point. Don't let it generate queued steps in the first place. // The gate system inside proposal-service.ts const STEP_KIND_GATES: Record<string, StepKindGate> = { write_content: checkWriteContentGate, // Check daily content cap post_tweet: checkPostTweetGate, // Check tweet quota deploy: checkDeployGate, // Check deploy policy }; Each step kind has its own gate. Tweet quota full? Proposal gets rejected immediately, reason clearly stated, warning event emitted. No queued step = no buildup. Here's the post_tweet gate: async function checkPostTweetGate(sb: SupabaseClient) { const autopost = await getOpsPolicyJson(sb, 'x_autopost', {}); if (autopost.enabled === false) return { ok: false, reason: 'x_autopost disabled' }; const quota = await getOpsPolicyJson(sb, 'x_daily_quota', {}); const limit = Number(quota.limit ?? 10); const { count } = await sb .from('ops_tweet_drafts') .select('id', { count: 'exact', head: true }) .eq('status', 'posted') .gte('posted_at', startOfTodayUtcIso()); if ((count ?? 0) >= limit) return { ok: false, reason: `Daily tweet quota reached (${count}/${limit})` }; return { ok: true }; } Key principle: Reject at the gate, don't pile up in the queue. Rejected proposals get recorded (for auditing), not silently dropped. ## Making It Alive: Triggers + Reaction Matrix With the three pitfalls fixed, the loop works. But the system is just an "error-free assembly line," not a "responsive team." Triggers 4 built-in rules — each detects a condition and returns a proposal template: ConditionActionCooldownTweet engagement > 5%Growth analyzes why it went viral2 hoursMission failedSage diagnoses root cause1 hourNew content publishedObserver reviews quality2 hoursInsight gets multiple upvotesAuto-promote to permanent memory4 hours Triggers only detect — they don't touch the database directly, they hand proposal templates to the proposal service. All cap gates and auto-approve logic apply automatically. Cooldown matters. Without it, one viral tweet would trigger an analysis on every heartbeat cycle (every 5 minutes). Reaction Matrix The most interesting part — spontaneous inter-agent interaction. A reaction_matrix stored in the ops_policy table: { "patterns": [ { "source": "twitter-alt", "tags": ["tweet","posted"], "target": "growth", "type": "analyze", "probability": 0.3, "cooldown": 120 }, { "source": "*", "tags": ["mission:failed"], "target": "brain", "type": "diagnose", "probability": 1.0, "cooldown": 60 } ] } Xalt posts a tweet → 30% chance Growth will analyze its performance. Any mission fails → 100% chance Sage will diagnose. probability isn't a bug, it's a feature. 100% determinism = robot. Add randomness = feels more like a real team where "sometimes someone responds, sometimes they don't." ## Self-Healing: Systems Will Get Stuck VPS restarts, network blips, API timeouts — steps get stuck in running status with nobody actually processing them. The heartbeat includes recoverStaleSteps: // 30 minutes with no progress → mark failed → check if mission should be finalized const STALE_THRESHOLD_MS = 30 * 60 * 1000; const { data: stale } = await sb .from('ops_mission_steps') .select('id, mission_id') .eq('status', 'running') .lt('reserved_at', staleThreshold); for (const step of stale) { await sb.from('ops_mission_steps').update({ status: 'failed', last_error: 'Stale: no progress for 30 minutes', }).eq('id', step.id); await maybeFinalizeMissionIfDone(sb, step.mission_id); } maybeFinalizeMissionIfDone checks all steps in the mission — any failed means the whole mission fails, all completed means success. No more "one step succeeded so the whole mission gets marked as success." ## Full Architecture Three layers with clear responsibilities: • OpenClaw (VPS): Think + Execute (brain + hands) • Vercel: Approve + Monitor (control plane) • Supabase: All state (shared cortex) ## What You Can Take Home If you have OpenClaw + Vercel + Supabase, here's a minimum viable closed-loop checklist: 1. Database Tables (Supabase) You need at least these: TablePurposeops_mission_proposalsStore proposals (pending/accepted/rejected)ops_missionsStore missions (approved/running/succeeded/failed)ops_mission_stepsStore execution steps (queued/running/succeeded/failed)ops_agent_eventsStore event stream (all agent actions)ops_policyStore policies (auto_approve, x_daily_quota, etc. as JSON)ops_trigger_rulesStore trigger rulesops_agent_reactionsStore reaction queueops_action_runsStore execution logs 2. Proposal Service (One File) Put proposal creation + cap gates + auto-approve + mission creation in one function. All sources (API, triggers, reactions) call it. This is the hub of the entire loop. 3. Policy-Driven Configuration (ops_policy table) Don't hardcode limits. Every behavior toggle lives in the ops_policy table: // auto_approve: which step kinds are allowed to auto-pass { "enabled": true, "allowed_step_kinds": ["draft_tweet","crawl","analyze","write_content"] } // x_daily_quota: daily tweet cap { "limit": 8 } // worker_policy: whether Vercel executes steps (set false = VPS only) { "enabled": false } Adjust policies anytime without redeploying code. 4. Heartbeat (One API Route + One Crontab Line) A /api/ops/heartbeat route on Vercel. A crontab line on VPS calling it every 5 minutes. Inside it runs: trigger evaluation, reaction queue processing, insight promotion, stale task cleanup. 5. VPS Worker Contract Each step kind maps to a worker. After completing a step, the worker calls maybeFinalizeMissionIfDone to check whether the entire mission should be finalized. Never mark a mission as succeeded just because one step finished. ## Two-Week Timeline PhaseTimeWhat Got DoneInfrastructurePre-existingOpenClaw VPS + Vercel + Supabase (already set up)Proposals + Approval3 daysProposals API + auto-approve + policy tableExecution Engine2 daysmission-worker + 8 step executorsTriggers + Reactions2 days4 trigger types + reaction matrixLoop Unification1 dayproposal-service + cap gates + fix three pitfallsAffect System + Visuals2 daysAffect rewrite + idle behavior + pixel office integrationSeed + Go LiveHalf dayMigrations + seed policies + crontab Excluding pre-existing infrastructure, the core closed loop (propose → execute → feedback → re-trigger) takes about one week to wire up. ## Final Thoughts These 6 agents now autonomously operate voxyz.space every day. I'm still optimizing the system daily — tuning policies, expanding trigger rules, improving how agents collaborate. It's far from perfect — inter-agent collaboration is still basic, and "free will" is mostly simulated through probability-based non-determinism. But the system genuinely runs, genuinely doesn't need someone watching it. Next article, I'll cover how agents "argue" and "persuade" each other — how roundtable voting and Sage's memory consolidation turn 6 independent Claude instances into something resembling team cognition. If you're building agent systems with OpenClaw, I'd love to compare notes. When you're an indie dev doing this, every conversation saves you from another pitfall.




Topics
Read the stories that matter.The stories and ideas that actually matter.
Save hours a day in 5 minutesTurn hours of scrolling into a five minute read.