GLM-5 Architecture Uses Multi-Head Latent Attention
Press Space for next Tweet
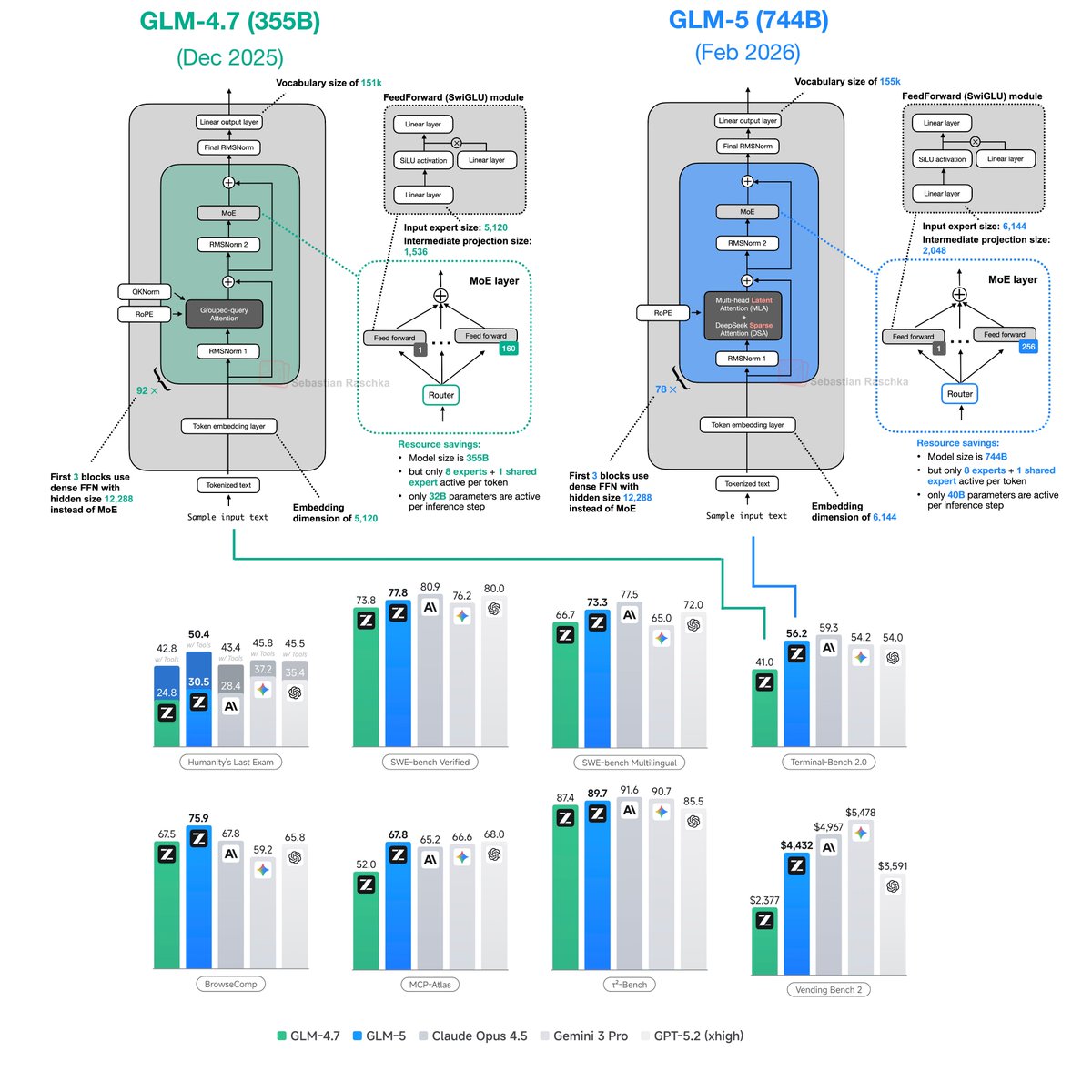
The weights are out! Here's the GLM-5 architecture comparison. GLM-5 is: - bigger than its predecessor (mainly more experts) but has rel. similar active parameter counts - uses multi-head latent attention - uses DeepSeek Sparse Attention
Topics
Read the stories that matter.The stories and ideas that actually matter.
Save hours a day in 5 minutesTurn hours of scrolling into a five minute read.