SWE-Bench Verified Has Flawed Tests and Data Leakage
Press Space for next Tweet
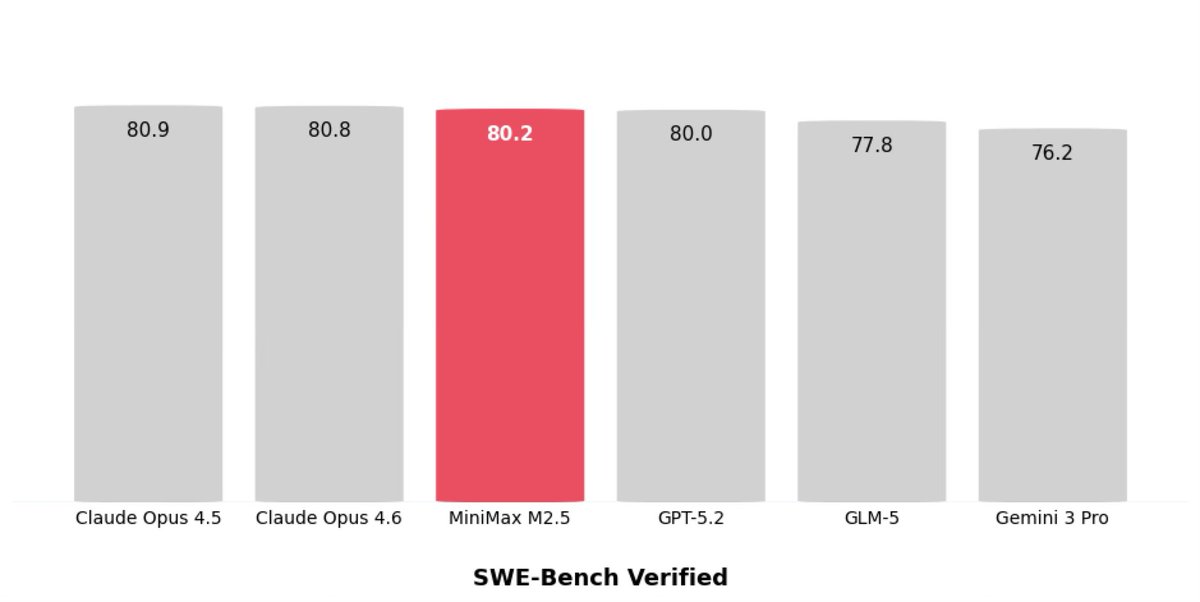
Am currently putting together an article, and yeah, the SWE-Bench Verified numbers are definitely a bit sus across all models -- the benchmark suggest they are more similar than they really are. So, I went down a rabbit hole looking into SWE-Bench Verified issues... And it looks like OpenAI already did really nice work there in their "Why SWE-bench Verified no longer measures frontier coding capabilities" analysis: https://openai.com/index/why-we-no-longe… The gist is: 1. After auditing 27.6% of frequently failed tasks, at least 59.4% had flawed tests that reject correct solutions 2. Since SWE-Bench draws from widely used open-source repos, frontier models sometimes reproduced the exact “gold patch” or problem details, which suggest data leakage. (Probably a "duh" given that the dataset has been out since 2023.) Long story short, SWE-Bench Pro seems to a bit of an improvement (for now).
Topics
Read the stories that matter.The stories and ideas that actually matter.
Save hours a day in 5 minutesTurn hours of scrolling into a five minute read.