Implementing Tiny Aya Language Model From Scratch
Press Space for next Tweet
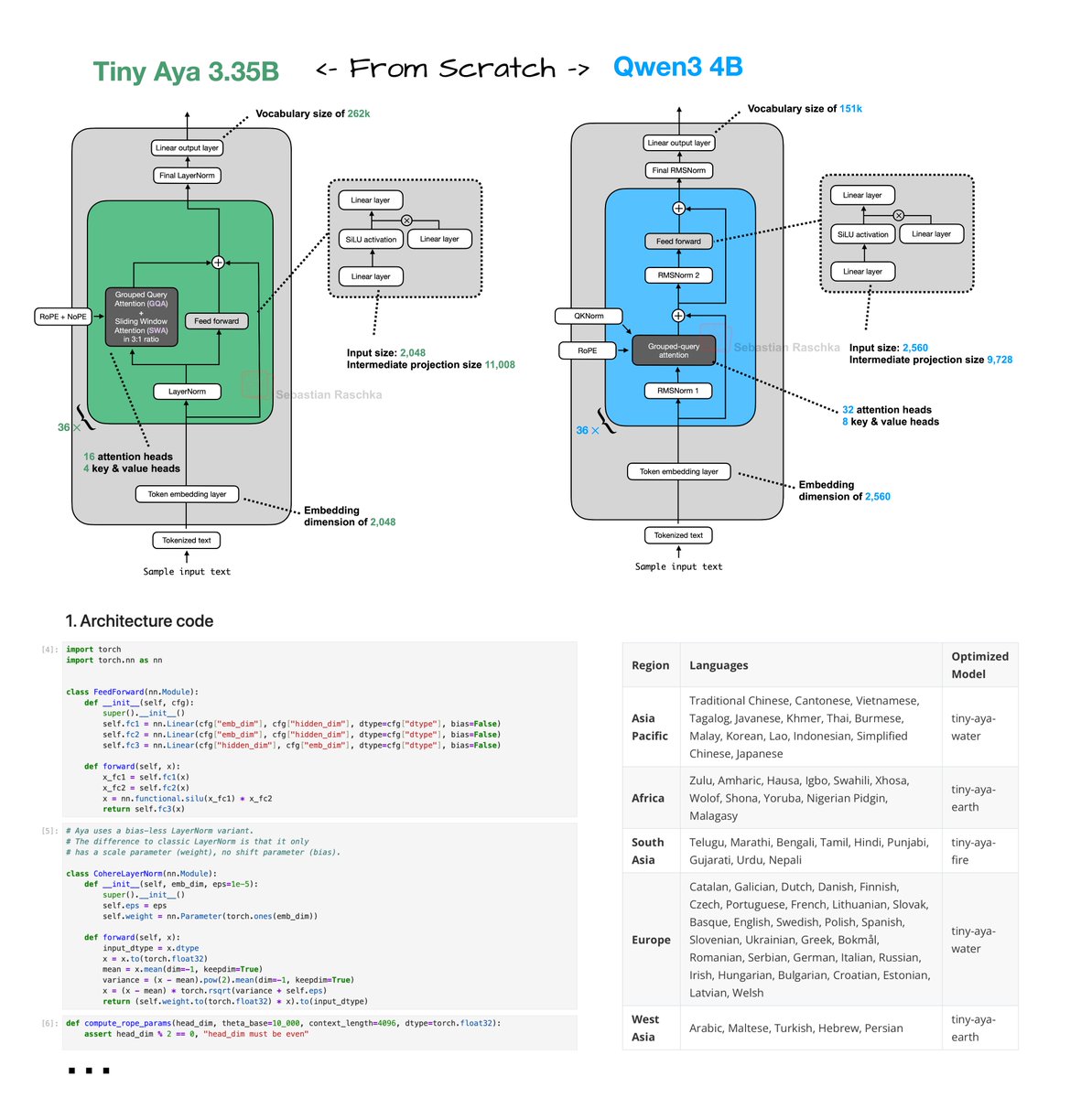
Tiny Aya reimplementation From Scratch! Have been reading through the technical reports of the recent wave of open-weight LLM releases (more on that soon). Tiny Aya (2 days ago) was a bit under the radar. Looks like a nice, small 3.35B model with strongest multilingual support of that size class. Great for on-device translation tasks. Just did a from-scratch implementation here: https://github.com/rasbt/LLMs-from-scrat… Architecture-wise, Tiny Aya is a classic decoder-style transformer with a few noteworthy modifications (besides the obvious ones like SwiGLU and Grouped Query Attention): 1. Parallel transformer blocks. A parallel transformer block computes attention and MLP from the same normalized input, then adds both to the residual in one step. I assume this is to reduce serial dependencies inside a layer to improve computational throughput. 2. Sliding window attention. Specifically, it uses a 3:1 local:global ratio similar to Arcee Trinity and Olmo 3. The window size is also 4096. Also, similar to Arcee, the sliding window layers use RoPE whereas the full attention layers use NoPE. 3. LayerNorm. Most architectures moved to RMSNorm as it's computationally a bit cheaper and performs well. Tiny Aya is keeping it more classic with a modified version of LayerNorm (the implementation here is like standard LayerNorm but without shift, i.e., bias, parameter).
Topics
Read the stories that matter.The stories and ideas that actually matter.
Save hours a day in 5 minutesTurn hours of scrolling into a five minute read.