Open-Weight LLM Architecture Trends January February 2026
Press Space for next Tweet
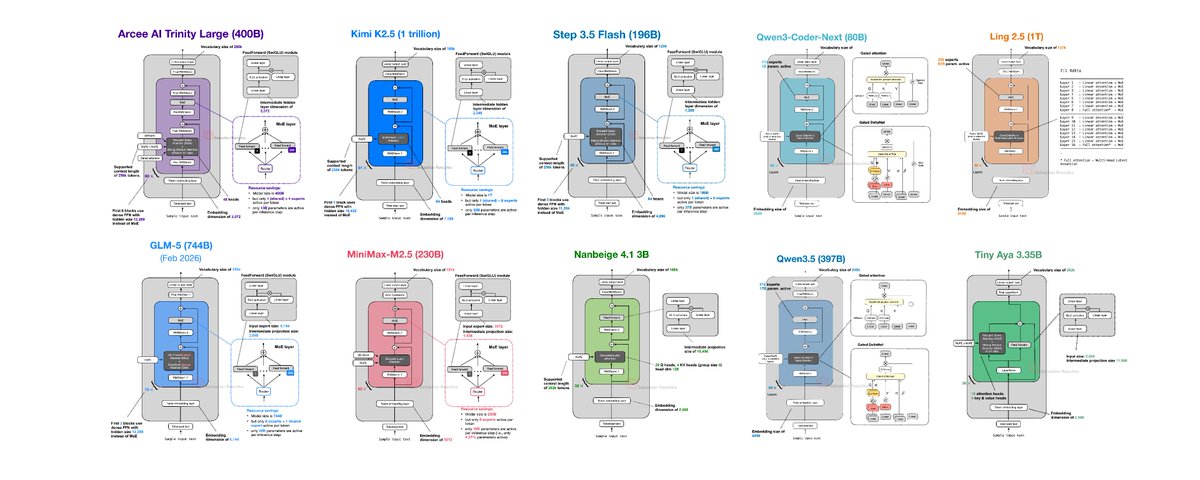
📝 10 open-weight LLM releases in January and February 2026 If you have struggled to keep up with open-weight releases this past month, here's an overview of the main ones in chronological order with a focus on the architecture designs. 1) Arcee AI Trinity Large (Jan 27) Arcee's Trinity line came out of nowhere for many of us. It's a 400B MoE (13B active), plus two smaller smaller variants. Architecturally, it combines familiar ingredients: Mixture-of-Experts (MoE) + Grouped Query Attention (GQA) + Sliding Window Attention (SWA). 2) Moonshot Kimi K2.5 (Jan 27) Similar to Kimi K2, Kimi K2.5 is one of the largest open-weight models at 1 trillion parameters. Also similar to Kimi K2, it follows a DeepSeek-like template. 3) StepFun Step 3.5 Flash (Feb 1) Step 3.5 Flash mainly focuses on performance-throughput balance. Overall, it is somewhat to Arcee Trinity in that it uses GQA + SWA, but it's 2x smaller. 4) Qwen3-Coder-Next (Feb 3) Qwen3-Coder-Next continues Qwen's focus on hybrid-attention for coding models. The architecture (and size) is similar to the previous 80B Qwen3-Next model, except it's fine-tuned for coding contexts. 5) z.AI GLM-5 (Feb 12) GLM-5 is a flagship-scale release that stays close to the current "large MoE + efficiency tweaks" consensus. It also includes DeepSceek-inspired choices (for example, MLA and DeepSeek Sparse Attention). 6) MiniMax M2.5 (Feb 12) MiniMax M2.5 is especially interesting because it is strong but staying mostly very classic with plain GQA. 7) Nanbeige 4.1 3B (Feb 13) Nanbeige 4.1 3B is one of the interesting "small" models of this release wave. It's essentially a Llama 3-style model (similar to the Qwen3 dense models). 8) Qwen3.5 (Feb 15) Qwen3.5 (397B-A17B) is interesting because it looks like that the Qwen team now also adopts the hybrid attention mechanism into their main (non-Next) line. 9) Ant Group Ling 2.5 / Ring 2.5 (Feb 16) Similar to Kimi, Ling/Ring 2.5 is also a 1 trillion parameter MoE. It's using a hybrid scheme with Lightning Attention plus MLA-style compression. Conceptually, it is somewhat similar to Qwen3.5 but with a slightly simpler linear-attention variant (compared to Gated DeltaNet). 10) Cohere Tiny Aya (Feb 17( Tiny Aya is a smaller multilingual model, but from an architecture perspective it uses an interesting parallel transformer block design. Summary Overview If there is one spring-2026 architecture takeaway, architectures are pretty much autoregressive transformer-centric. There's nothing completely new (but hey, DeepSeek V4 is not out, yet). However, we are seeing more and more architectures moving from the more classic GQA to MLA and even linear attention hybrids, which means that efficiency (lower latency and longer context performance scaling) is becoming more and more important. This was an abbreviated whirlwind tour of a much longer and detailed article. If you are interested, you can read more in "A Dream of Spring for Open-Weight LLMs: 10 Architectures from Jan-Feb 2026": https://magazine.sebastianraschka.com/p/… http://x.com/i/article/20265036538932224…
Topics
Read the stories that matter.The stories and ideas that actually matter.
Save hours a day in 5 minutesTurn hours of scrolling into a five minute read.