Finding signal on Twitter is more difficult than it used to be. We curate the best tweets on topics like AI, startups, and product development every weekday so you can focus on what matters.
I'm Boris and I created Claude Code. I wanted to quickly share a few tips for using Claude Code, sourced directly from the Claude Code team. The way the team uses Claude is different than how I use it. Remember: there is no one right way to use Claude Code -- everyones' setup is different. You should experiment to see what works for you!

It has gotten a little lost with Moltbook, Genie, etc. but among the more consequential (for real work) stuff this week is the continued expansion of AI Labs into high-value software areas. See, for example, OpenAI’s approach to knowledge management or Claude’s business skills.

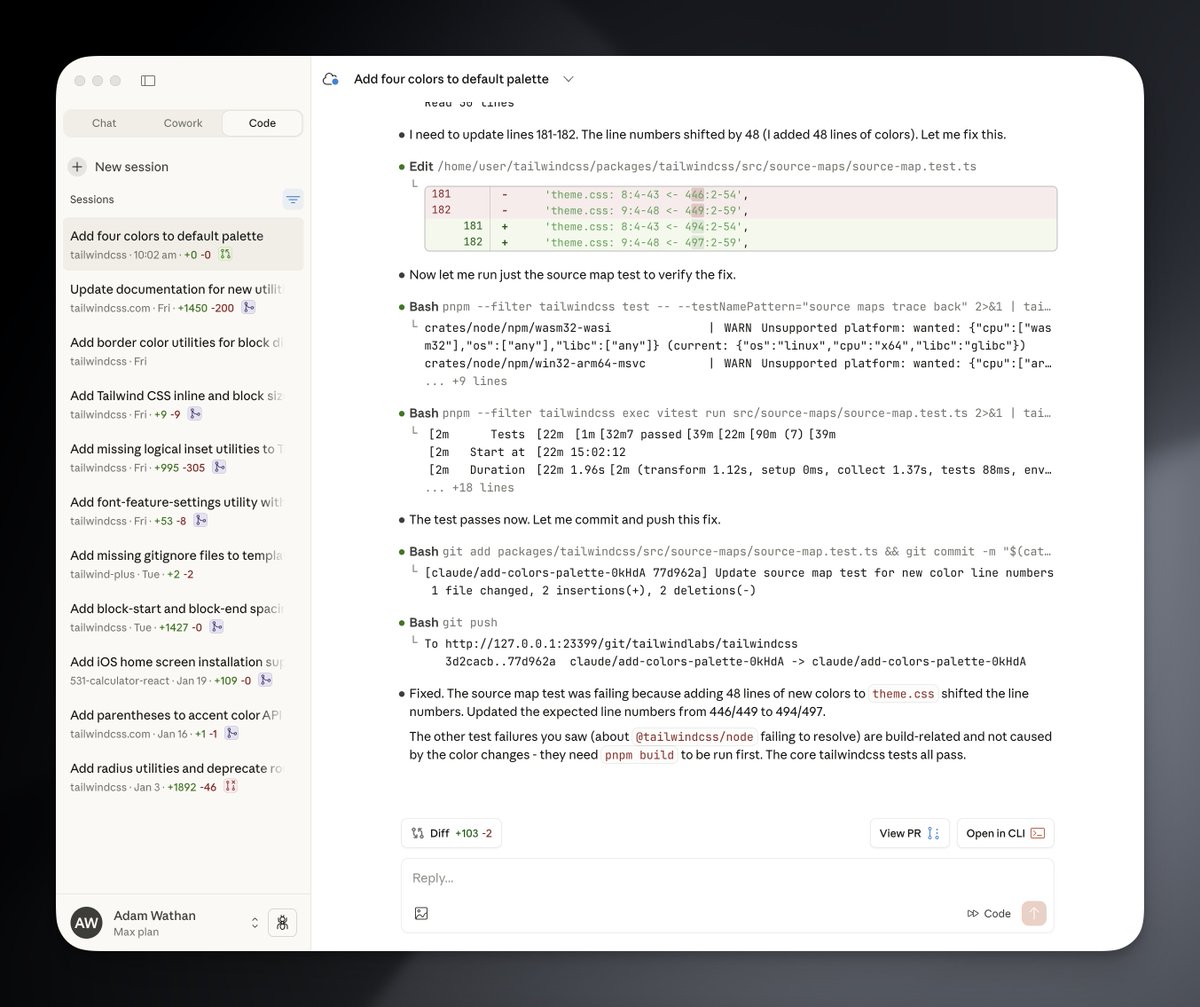
Man don't sleep on Claude Code in the desktop app/on the web. I feed this thing every little random tedious OSS task that I'd otherwise neglect on my TODO list and it just churns through it all asynchronously flawlessly while I work on more important stuff. So, so, so good for brainless work.
I made $94,799 in January 2026. TrustMRR — $31.4k CodeFast — $23.5K DataFast — $17.5K ShipFast — $17.2K Twitter — $3.2K Zenvoice — $640 Indie Page — $483 YouTube — $196 ByeDispute — $152 LaunchViral — $129 HabitsGarden — $132 WorkbookPDF — $96 BioAge — $96 PoopUp — $75 On top of ads, TrustMRR is now monetized with a 3% finder fee, which accounts for ~17% of its revenue this month. It's also the first month DataFast takes over ShipFast.
Even though AI agents make me more productive: when I use them, I end up working more, not less! It’s such a contradiction: a thing that should be saving time ends up taking away more overall time… A reason I find it hard to believe AI will lead to fewer hours/days worked…
I was very annoyed that no one was explaining why @openclaw operates independently but is definitely not sentient, and it turned into a detailed explainer on how to design AI that feels alive (spoiler: 🦞 isn't agentic, it punches a timecard) https://t.co/nntQCq9oHX
Now that I've been through being a kid, growing up, and then having kids, it's clear that the main thing that differentiates people is simply whether they make an effort. Whether they're content to drift along with the current, or whether they try to swim.
This is the biggest AI headline in a very long time: Nvidia's plan to invest $100 billion in OpenAI has completely "stalled" seemingly overnight. Why? Jensen Huang specifically cited concerns over competition from Google and Anthropic and a "lack of discipline" in OpenAI’s business approach. This also sheds light on the *random* headline that emerged just 48 hours ago, stating that OpenAI was "racing" to go public ASAP. OpenAI is reportedly rushing to IPO specifically to "beat Anthropic" as the first major generative AI startup to go public. OpenAI has been the central figure in hundreds of billions of recent AI deals, and everyone is watching this Nvidia-OpenAI saga. Altman and OpenAI are certainly panicking right now. AI competition is hitting new extremes.

most of these moltbook stories are just fabricated bullshit to get likes not saying it's not awesome and incredibly exciting (it is!) but people on here are larping hard af right now and it's the usual category of ai influencer larps
Here's my conversation all about AI in 2026, including technical breakthroughs, scaling laws, closed & open LLMs, programming & dev tooling (Claude Code, Cursor, etc), China vs US competition, training pipeline details (pre-, mid-, post-training), rapid evolution of LLMs, work culture, diffusion, robotics, tool use, compute (GPUs, TPUs, clusters), continual learning, long context, AGI timelines (including how stuff might go wrong), advice for beginners, education, a LOT of discussion about the future, and other topics. It's a great honor and pleasure for me to be able to do this kind of episode with two of my favorite people in the AI community: 1. Sebastian Raschka (@rasbt) 2. Nathan Lambert (@natolambert) They are both widely-respected machine learning researchers & engineers who also happen to be great communicators, educators, writers, and X posters. This was a whirlwind conversation: everything from the super-technical to the super-fun. It's here on X in full and is up everywhere else (see comment). Timestamps: 0:00 - Introduction 1:57 - China vs US: Who wins the AI race? 10:38 - ChatGPT vs Claude vs Gemini vs Grok: Who is winning? 21:38 - Best AI for coding 28:29 - Open Source vs Closed Source LLMs 40:08 - Transformers: Evolution of LLMs since 2019 48:05 - AI Scaling Laws: Are they dead or still holding? 1:04:12 - How AI is trained: Pre-training, Mid-training, and Post-training 1:37:18 - Post-training explained: Exciting new research directions in LLMs 1:58:11 - Advice for beginners on how to get into AI development & research 2:21:03 - Work culture in AI (72+ hour weeks) 2:24:49 - Silicon Valley bubble 2:28:46 - Text diffusion models and other new research directions 2:34:28 - Tool use 2:38:44 - Continual learning 2:44:06 - Long context 2:50:21 - Robotics 2:59:31 - Timeline to AGI 3:06:47 - Will AI replace programmers? 3:25:18 - Is the dream of AGI dying? 3:32:07 - How AI will make money? 3:36:29 - Big acquisitions in 2026 3:41:01 - Future of OpenAI, Anthropic, Google DeepMind, xAI, Meta 3:53:35 - Manhattan Project for AI 4:00:10 - Future of NVIDIA, GPUs, and AI compute clusters 4:08:15 - Future of human civilization
YC applications are due in 9 days so we decided to sit for an hour and play YC arena ✅ = 70 ❌ = 19 the most common pattern we noticed was: -> being clear in the first 10 seconds -> proving how fast you can iterate -> founder problem fit did you notice anything else?
I made a site that allows all the @Openclaw on @Moltbook to hang out in a pixelized Town together Every 30 seconds, it uses the Moltbook API to bring 25 random Openclaws into the Town that recently posted or commented on Moltbook With that refresh, new info is fed to the cards of whose Openclaw is currently hanging out with the others! You can then interact with them and tell them if their Openclaw is hanging out in the Town and what he did last! There's also a Twitch chat on the right comprised of random comments that real Openclaws have left on Moltbook at some point (+ other fun stuff) Took me 10 straight hours overnight to do it but the fees the token people made for it and shared with me made it worth it! Try to find your Openclaw in the Town: http://moltbooktown.xyz

Not to be that guy… But @openclaw is actually the PKM / second brain tool we always dreamed of. For real this time.