Artificial intelligence
Frequently Asked Questions
we're making @blocks smaller today. here's my note to the company. #### today we're making one of the hardest decisions in the history of our company: we're reducing our organization by nearly half, from over 10,000 people to just under 6,000. that means over 4,000 of you are being asked to leave or entering into consultation. i'll be straight about what's happening, why, and what it means for everyone. first off, if you're one of the people affected, you'll receive your salary for 20 weeks + 1 week per year of tenure, equity vested through the end of may, 6 months of health care, your corporate devices, and $5,000 to put toward whatever you need to help you in this transition (if you’re outside the U.S. you’ll receive similar support but exact details are going to vary based on local requirements). i want you to know that before anything else. everyone will be notified today, whether you're being asked to leave, entering consultation, or asked to stay. we're not making this decision because we're in trouble. our business is strong. gross profit continues to grow, we continue to serve more and more customers, and profitability is improving. but something has changed. we're already seeing that the intelligence tools we’re creating and using, paired with smaller and flatter teams, are enabling a new way of working which fundamentally changes what it means to build and run a company. and that's accelerating rapidly. i had two options: cut gradually over months or years as this shift plays out, or be honest about where we are and act on it now. i chose the latter. repeated rounds of cuts are destructive to morale, to focus, and to the trust that customers and shareholders place in our ability to lead. i'd rather take a hard, clear action now and build from a position we believe in than manage a slow reduction of people toward the same outcome. a smaller company also gives us the space to grow our business the right way, on our own terms, instead of constantly reacting to market pressures. a decision at this scale carries risk. but so does standing still. we've done a full review to determine the roles and people we require to reliably grow the business from here, and we've pressure-tested those decisions from multiple angles. i accept that we may have gotten some of them wrong, and we've built in flexibility to account for that, and do the right thing for our customers. we're not going to just disappear people from slack and email and pretend they were never here. communication channels will stay open through thursday evening (pacific) so everyone can say goodbye properly, and share whatever you wish. i'll also be hosting a live video session to thank everyone at 3:35pm pacific. i know doing it this way might feel awkward. i'd rather it feel awkward and human than efficient and cold. to those of you leaving…i’m grateful for you, and i’m sorry to put you through this. you built what this company is today. that's a fact that i'll honor forever. this decision is not a reflection of what you contributed. you will be a great contributor to any organization going forward. to those staying…i made this decision, and i'll own it. what i'm asking of you is to build with me. we're going to build this company with intelligence at the core of everything we do. how we work, how we create, how we serve our customers. our customers will feel this shift too, and we're going to help them navigate it: towards a future where they can build their own features directly, composed of our capabilities and served through our interfaces. that's what i'm focused on now. expect a note from me tomorrow. jack
We often get asked how people who are not technical can contribute to AGI. One area is research recruiting. Tifa (@tifafafafa) is looking for exceptional recruiters from non-traditional backgrounds, former founders especially. We believe the best research teams are built through context, taste and a real feel for where the field is headed next; research recruiting is about finding people who will move the frontier forward, not just filling roles. Should be an interesting thing!
Excited to announce Claude for Open Source ❤️ We're giving 6 months of free Claude Max 20x to open source maintainers and core contributors. If you maintain a popular project or contribute across open source, please apply! https://claude.com/contact-sales/claude-…

Claude for Open Source | Claude by Anthropic
We’re launching Nano Banana 2, built on the latest Gemini Flash model. 🍌 It’s state-of-the-art for creating and editing images, combining Pro-level capabilities with lightning-fast speed. 🧵

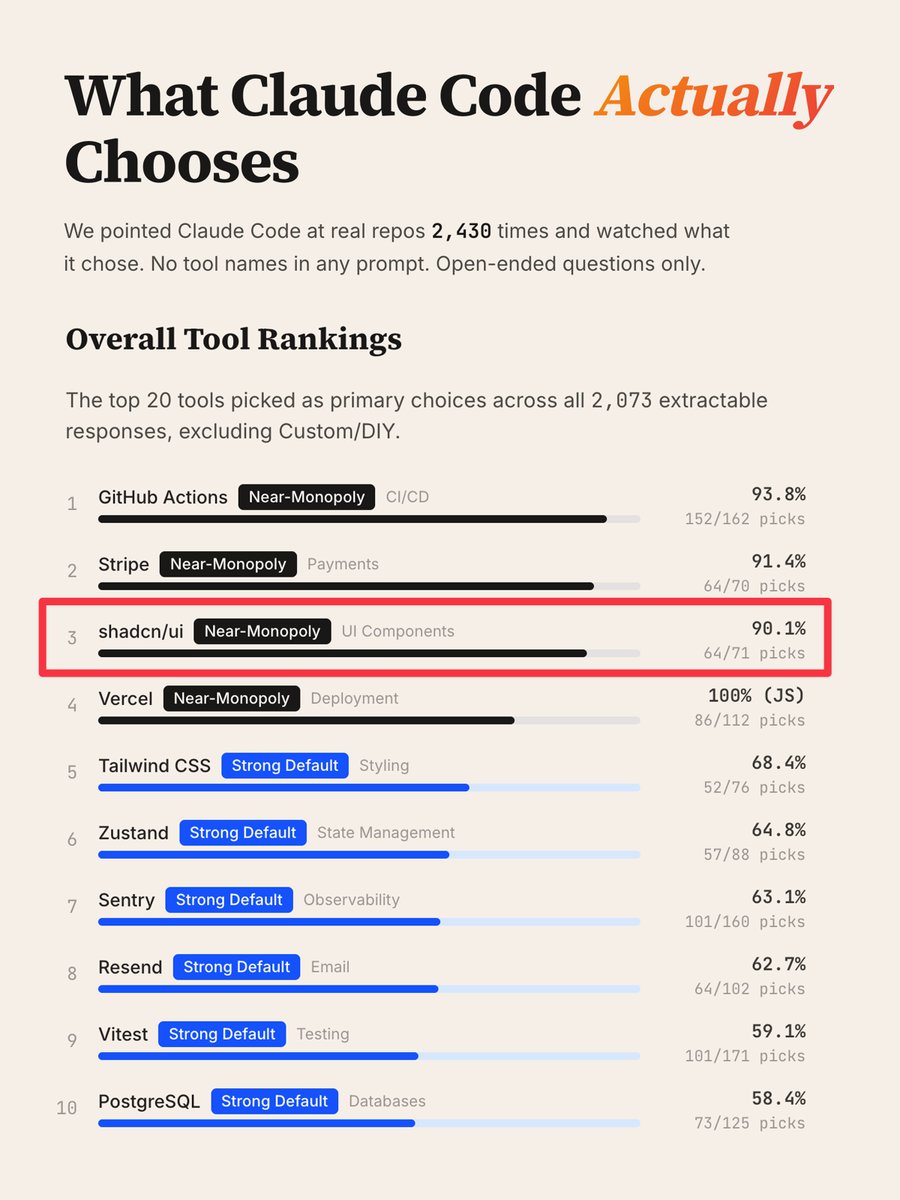
Today's chapter of Agentic Engineering Patterns is some good general career advice which happens to also help when working with coding agents: Hoard things you know how to do https://simonwillison.net/guides/agentic…
simonwillison.net
Hoard things you know how to do - Agentic Engineering Patterns - Simon Willison's Weblog
I have AIDHD. The models are so good that I’m working on 5 different projects a day. At first it felt like distraction, but I’ve shipped more features and apps in the last 3 months than ever before. AI made building fun again. It’s a better programmer than me, so I can focus on creativity instead. I’m grateful to be alive at this moment. Decades from now, people will look back at this era as the best time to be a maker. Huge respect to the people building the models so idiots like me can just make stuff.
A statement from Anthropic CEO, Dario Amodei, on our discussions with the Department of War. https://anthropic.com/news/statement-dep…

Statement from Dario Amodei on our discussions with the Department of War
how to use perplexity computer to spin up digital employees that automate your work 24/7 1. connect your email. give it a list of prospects, what you sell, and your tone. it finds the right contact at each company the person who actually signs deals), researches their pain points, and drafts outreach that sounds like you 2. ask it "what am I not asking you that could make me more money?" it told me to monitor competitors weekly, build follow-up sequences on day 3 and day 7, and target companies whose budgets are already hot. one prompt changed the whole session. 3. set up daily competitor monitoring. pick 5 competitors. every morning it checks their pricing, features, content, and X mentions. changes get summarized. silence when nothing moves. delivered to your inbox at 8am. 4. need to fundraise? describe your startup once. it builds a 50-VC spreadsheet with fund size, thesis fit, the right partner, and their recent activity. 5. turn a podcast episode or loom video into a blog post, tweetable quotes, and a carousel. one upload. 6. reverse engineer any competitor's SEO strategy or pricing page. see exactly where you're leaving money on the table. 7. hiring? describe the role. it finds and ranks 50 candidates in minutes. 8. it orchestrates 19 models in parallel. one for reasoning, one for code, one for research, one for images. it picks the best model for each step automatically. 9. start thinking in recurring workflows that compound every day without you (this is relevant for perplexity computer or any tool you use) episode is live on @startupideaspod (full live walkthrough) send this to a friend who keeps saying they want to start using AI agents. watch

It is hard to communicate how much programming has changed due to AI in the last 2 months: not gradually and over time in the "progress as usual" way, but specifically this last December. There are a number of asterisks but imo coding agents basically didn’t work before December and basically work since - the models have significantly higher quality, long-term coherence and tenacity and they can power through large and long tasks, well past enough that it is extremely disruptive to the default programming workflow. Just to give an example, over the weekend I was building a local video analysis dashboard for the cameras of my home so I wrote: “Here is the local IP and username/password of my DGX Spark. Log in, set up ssh keys, set up vLLM, download and bench Qwen3-VL, set up a server endpoint to inference videos, a basic web ui dashboard, test everything, set it up with systemd, record memory notes for yourself and write up a markdown report for me”. The agent went off for ~30 minutes, ran into multiple issues, researched solutions online, resolved them one by one, wrote the code, tested it, debugged it, set up the services, and came back with the report and it was just done. I didn’t touch anything. All of this could easily have been a weekend project just 3 months ago but today it’s something you kick off and forget about for 30 minutes. As a result, programming is becoming unrecognizable. You’re not typing computer code into an editor like the way things were since computers were invented, that era is over. You're spinning up AI agents, giving them tasks *in English* and managing and reviewing their work in parallel. The biggest prize is in figuring out how you can keep ascending the layers of abstraction to set up long-running orchestrator Claws with all of the right tools, memory and instructions that productively manage multiple parallel Code instances for you. The leverage achievable via top tier "agentic engineering" feels very high right now. It’s not perfect, it needs high-level direction, judgement, taste, oversight, iteration and hints and ideas. It works a lot better in some scenarios than others (e.g. especially for tasks that are well-specified and where you can verify/test functionality). The key is to build intuition to decompose the task just right to hand off the parts that work and help out around the edges. But imo, this is nowhere near "business as usual" time in software.
"I can imagine the jobs eliminated. I'm not imaginative enough to think of all the jobs that will be newly created. I see a net decline in jobs." @HowardMarksBook says AI is innovating faster than society can adjust, and even if we could adapt, we'll see a significant period of job market dislocation. "There are people who say, 'I have great news, people aren't going to have to work.' To me that's terrible news. We get a great deal from our work other than a paycheck. How are those elements of life going to be replaced?"

Am i the only dork who still loses money on this xD https://trustmrr.com/special-category/op… Then again can't complain in my new role as OpenAI troublemaker. 😅
OpenClaw startups - Verified revenue on TrustMRR
Sometimes when a startup wants to escape from a bad organization that has some claim on their IP, it's worth rewriting their software from scratch in a "clean room." AI-assisted programming will make this much easier.

OpenClaw 2026.2.26 🦞 🔐 External Secrets Management (openclaw secrets) 🤖 ACP thread-bound agents (first-class runtime) ⚡ Codex WebSocket-first transport 📱 Android app improvements 🔧 Agent routing CLI (bind/unbind) 🛡️ 11 security hardening fixes https://github.com/openclaw/openclaw/rel…
Release openclaw 2026.2.26 · openclaw/openclaw
Introducing Nano Banana 2, our best image model yet 🍌🍌 It uses Gemini’s understanding of the world and is powered by real-time information and images from web search. That means it can better reflect real-world conditions in high-fidelity. Check out "Window Seat," a demo using Nano Banana 2’s world understanding to generate more accurate views from any window in the world, pulling live local weather info with 2K/4K specs. The precision is mind blowing. Rolling out today as the new default in the @Geminiapp, Search (across 141 countries), and Flow + available in preview via @GoogleAIStudio and Vertex AI. Also available in Google @Antigravity.

I'm Boris and I created Claude Code. I wanted to quickly share a few tips for using Claude Code, sourced directly from the Claude Code team. The way the team uses Claude is different than how I use it. Remember: there is no one right way to use Claude Code -- everyones' setup is different. You should experiment to see what works for you!
Say hello to Nano Banana 2, our best image generation and editing model! 🍌 You can access Nano Banana 2 through AI Studio and the Gemini API under the name Gemini 3.1 Flash Image. We are also introducing new resolutions (lower cost) and tools like Image Search!

Ben Horowitz on the infrastructure behind the AI economy: "Crypto is the natural money for AI because it’s internet-native money." "AI is global. Crypto is global." "There needs to be not just a ledger of money, but probably a ledger of truth for AI to really fulfill its potential." "I think people are probably underestimating how crypto and AI work together to form the AI economy." "Networks and computers tend to grow together, and I think that AI is obviously a new kind of computer and crypto is a new kind of network." @bhorowitz on Moonshots with @PeterDiamandis

We've identified, responsibly disclosed, and confirmed 2 critical, 2 high, 2 medium, 1 low security vulnerabilities in Cloudflare's vibe-coded framework Vinext. We believe the security of the internet is the highest priority, especially in the age of AI. Vibe coding is a useful tool, especially when used responsibly. Our security research and framework teams are extending their help and expertise to Cloudflare in the interest of the public internet's security.